Swift Playgroundsで学ぶiOSプログラミング 第65回
AVSpeechSynthesizerを利用
iPadに日本語と英語をしゃべらせるプログラム
2017年12月06日 17時00分更新

今回は、前回のQRコードの読み取り機能とはまったく毛色の異なるものとして、iPadに人間の言葉を発声させる機能、つまりスピーチシンセサイザーを取り上げます。
まったく関係なさそうな両機能ですが、実は大きな共通点があります。それはいずれもAVFoundationというフレームワークに含まれていることです。言うまでもなく、QRコードのほうが「V(isual)」で、スピーチシンセサイザーのほうは「A(udio)」です。この事実から、AVFoundationの守備範囲の広さがうかがえるというものです。
AVFoundationのスピーチシンセサイザー機能は、日本語や英語など、いわゆる自然言語の文を表す文字列を入力すると、それを人間の声に近い音声で読み上げてくれるというものです。その際、日本語と英語では発音の仕方がまったく異なるので、言語を変えるには、人間なら話者に相当する擬似的な人格を変更する必要のあるのは面白いところです。人間なら2カ国語を自由に操る人もそれほど珍しくありませんが、AVFoundationのスピーチシンセサイザーの中には、今のところバイリンガルの人はいないようです。
スピーチシンセサイザーは、人間の発声を摸したものなので、そこにはどうしても「個性」というものが芽生えます。そのためもあって、シンセサイザーの話者には人間と同じような名前が付いています。話者ごとに声質も違い、名前と対応させて区別することができます。その中には男性も女性もいます。
今回は実験的なプログラムで、まずiPadに日本語をしゃべらせてみてから、言語を変えて英語をしゃべらせます。そのあと、同じ日本語でも異なる話者の音声をしゃべり分けられるようにしてみます。
まずは日本語の文をしゃべらせてみる
スピーチシンセサイザーを使う最小限のプログラムから始めましょう。入力した日本語の文字列をしゃべらせるというものです。特に画面表示はありません。以前にも出てきましたが、このようにPlaygroundsのライブビューを使わずに、時間のかかる処理を実行するためには、現在のプレイグラウンドページのneedsIndefiniteExecutionというプロパティをtrueに設定しておく必要があります。
実際の発声は、まずAVSpeechSynthesizerクラスのオブジェクトを作り、それにAVSpeechUtteranceというクラスのオブジェクトを与えてしゃべらせます。

AVFoundationのAVSpeechSynthesizerを使って日本語をしゃべらせるための最小限のプログラムです。しゃべらせる内容はAVSpeechUtteranceのオブジェクトで指定します
Utteranceというのは「発声」のことです。そのオブジェクトは、しゃべらせる内容の文字列を指定して作ります。
このプログラムを実行すると、女性の声で、指定した日本語の文章を発声します。
AVSpeechUtteranceのオブジェクトは、話す内容だけでなく、声の性質、話し方などの情報も含んでいます。話す速さはrate、声の高さはpitchMultiplier、声の大きさはvolumeというプロパティで、それぞれ設定できます。rateのデフォルト値は、AVSpeechUtteranceDefaultSpeechRateという定数で決められていますが、現状では0.5のようです。それより数字が大きければ標準より速く、小さければ遅くしゃべります。pitchMultiplierのデフォルト値は1.0で、それより大きければ標準より高い声に、小さければ低い声になります。volumeは1.0がデフォルトで、それが最大です。それ以下の数字を指定することで、小さな声になります。
適当に設定を変えて試してみてください。
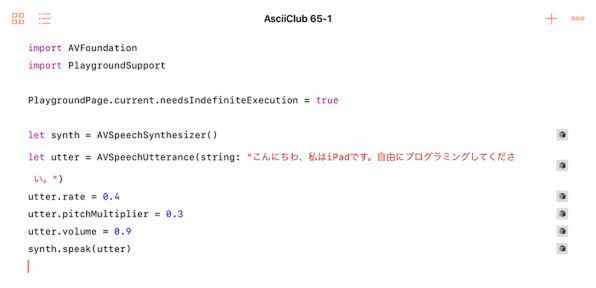
しゃべる際の速さ、声の高さ、大きさなどはAVSpeechUtteranceオブジェクトのプロパティとして簡単に設定できます
声を低くすると、男性的な声にも聞こえますが、別に男声も用意されています。それについては、少し後で取り上げます。
この連載の記事
- 第100回 SceneKitの物理現象シミュレーションとアニメーションをARKitに持ち込む
- 第99回 「物理学体」と「物理学場」を設定して物理現象をシミュレーション
- 第98回 SceneKitのノードに動きを加えるプログラム
- 第97回 いろいろな形のノードをシーンの中に配置する
- 第96回 SceneKitの基礎シーンビュー、シーン、ノードを理解する
- 第95回 現実世界の床にボールや自動車のモデルを配置する
- 第94回 ARKitを使って非現実世界との融合に備える
- 第93回 ARKitが使えるiPadを識別するプログラム
- 第92回 Swift Playgrounds 2.1での問題点をまとめて解消する
- 第91回 iPadの内蔵カメラで撮影した写真を認識するプログラム
- この連載の一覧へ

























