



クラウドから「エッジ」への動きが加速:Build/de:code 2019レポート 第10回
MSRAの自然言語コンピューティングの開発トップが説明
なぜ日本語の機械翻訳や音声認識は精度が低いのか
2019年06月03日 09時30分更新

日本マイクロソフトが2019年5月29日~30日、開発者向け年次イベント「de:code 2019」を開催した。イベントで「マイクロソフトリサーチのAI/自然言語処理研究最前線」のセッションを担当したMSRA Assistant Managing Director, Dr. Ming Zhou(周 明)氏は、マイクロソフト ディベロップメントと連携し、中国語および日本語向けMicrosoft IMEの開発に携わっている。
周氏は1999年9月にMicrosoft Research China(現MSRA: Microsoft Research Asia)に参加。同氏が率いるNLC(自然言語コンピューティング)グループは中国語-英語の機械翻訳エンジン、Xiaoice(中国版りんな)など多数のソリューション開発に関わってきた。他方でコンピューター言語/自然言語処理研究学会であるACL(Association of Computational Linguistics)会長や、CCF(Chinese Computer Federation: 中国計算机学会)中国情報技術委員会委員長、中国情報処理学会理事なども務める。日本マイクロソフトが2019年5月30日に開催したプレスラウンドテーブルで、周氏はMSRAのAI研究概要や自然言語処理研究の最新動向を説明した。

MSRA Assistant Managing Director, Dr. Ming Zhou(周 明)氏
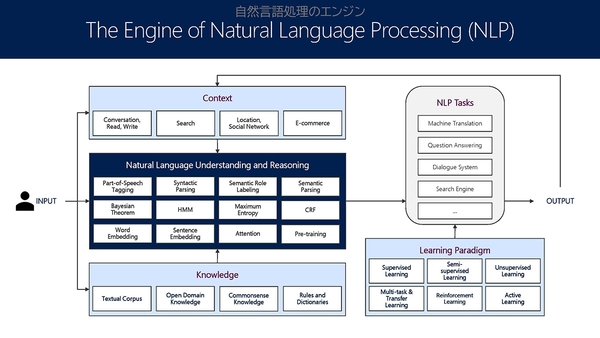
ナチュラルUI、AI、マルチメディア、ビッグデータ&ナレッジマイニング、クラウド&コンピューティング、コンピューターサイエンスファンデーションの6分野を研究対象とするMSRAは、昨年2018年11月で20周年を迎えた。その研究結果は多くのMicrosoft製品・サービスに活用されている。長年NLP(自然言語処理)の推進と発展に注力した周氏たちの努力は、日本語および中国語IMEやSkype Translator、Bing Dictionary、Web翻訳、Kinect for Windowsを用いた手話認識システム、BingやCortanaにおける会話やドキュメントの理解、エモーショナルチャットボットとして有名なりんななど、枚挙に暇がない。

セッションでモデレーターを務めた日本マイクロソフト 執行役員 最高技術責任者 兼 マイクロソフト ディベロップメント 代表取締役 社長 榊原彰氏
多くの場面で日本マイクロソフトはMicrosoft AIの成果をアピールしてきた。その一部はMSRAの研究結果によるNLPの飛躍的な進歩がもたらした成果である。2016年にはRESNETビジョンテストで画像認識率96%を実現し、2018年9月にはSQuAD(Stanford Question Answering Dataset)の機械読解力テストで人間のEM&F1スコアを上回った。2018年3月には機械翻訳テストも人間の68.5%を上回る69.9%に達し、MSRAは「ニュースの分野においては人間と同等」(周氏)と説明する。2018年6月のOCRテストもMSRAが開発したOneOCRのエラー率は競合ソリューションと比較して、50%のエラー削減に成功した。これらの成果は製品チームと協力し、各製品やサービスに活用されているという。

MSRAによる研究成果
NLPのプロジェクトがスタートしたのは2006年のこと。2008年に開発した英語援助検索エンジンEngkooは翌年2009年にBing Dictionaryとしてシステムに統合し、2010年にはMicrosoft Translatorの機能向上に大きく寄与した。2012年には、当時Microsoft Researchの研究統括責任者を務めていたRichard Rashid氏が、同氏のスピーチをテキスト化して中国語にリアルタイム翻訳するデモンストレーションを行った。その後、Microsoft Cognitive ServicesからSpeech to Textが登場し、Skype Translatorやニューラル機械翻訳、広東語翻訳で人間を上回る性能を打ち出すまでに至った。
MSRAのNLPエンジンは統計機械翻訳、ニューラル機械翻訳両者を提供している
日本語を使用する我々としては、言語学習に労せずに英語や中国語を日本語として読み聞きできれば、何もいうことはない。MSRAも「すべての言語間の翻訳を実現したい」(周氏)と述べるものの、これは容易ではないという。下図に示したのは英語を軸にした各言語の単語をリソースとして示したグラフだ。フランス語や中国語は多くのデータ量を持つのに対して、スウェーデン語以降は急減している。そのためMSRAは2言語の直接的な機械翻訳だけでなく、他言語を介した複数の機械翻訳手法を用いているという。

複数の機械翻訳手法を用いて多言語翻訳を実現する
だが、だが、英語-日本語の機械翻訳に、前述の他言語を介する手法は使えないそうだ。「構造が違う」(周氏)からだ。確かに日本語は主語+目的語+動詞だが、英語は主語+動詞+目的語が一般的だ。加えて目的語から始まるケースや修飾子が文末に続くこともある。さらには敬語や機能語も加わるため、「特別な扱いが必要だ」(周氏)。同研究所はエラー内容を分析し、言葉の乱れ(44.7%)や単語選択のミス(31%)などを検出し、日本語翻訳時の精度向上を目指しているという。正しい日本語という文脈で見ると、言葉は時代によって変化する。特にソーシャルネットワークやテキストチャットが日常化する現在では、文法や単語の乱れも見受けられるが、50年も使われ続けば、それはすでに"正しい言葉"である。このような変化に追従可能か別の記者から質問が上がると、「我々の技術はデータドリブン。データさえあれば分断された単語にも対応できる」(周氏)と自信を見せた。
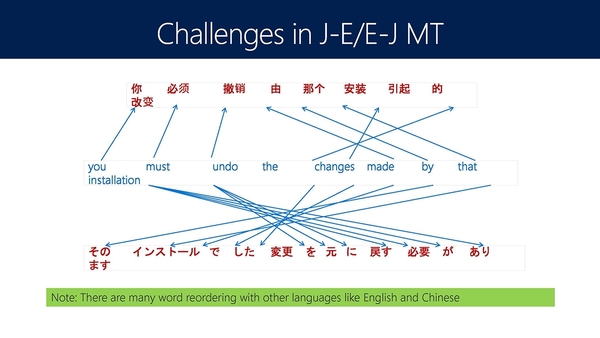
英語→中国語は語順に一貫性があるものの、英語→日本語は語順の入れ替えが多発するため、機械翻訳が難しいとMSRAは説明した
改めて日本語の扱いが難しいことを明示したプレスラウンドテーブルだったが、プロジェクトがスタートした2006年から12年間で人間の能力を上回った機械翻訳ソリューションを鑑みれば、"日本語の壁"もテクノロジーが打ち破るその日がいつか来るはずだ。
この連載の記事
-
第14回
クラウド
PWA、ML Ops、マイクロサービス――最も”今どき”なスマホアプリ開発を実演 -
第13回
クラウド
クラウド化は不可避な流れ、.NETアプリをクラウドネイティブへ移行するには -
第12回
TECH
「Internet of Human」の未来を体験――de code 2019のEXPOエリアで衝撃を受けた -
第11回
TECH
C#ライブコーディング対決!Blazor Web開発バトルが面白すぎた -
第9回
クラウド
デモで解説!「Visual Studio 2019」の新機能 ~GitHub、Azureと華麗に連携~ -
第8回
クラウド
WindowsにLinuxカーネルが入るとWeb開発が変わる――de:code 2019基調講演で「WSL2」をデモ -
第7回
クラウド
アーキテクチャ図でみる、Azureブロックチェーンを使ったスタバの珈琲豆トレーサビリティ -
第6回
クラウド
ソニーも注目したマイクロソフトの「Game Platform」とは -
第5回
TECH
Build 2019でのFluent Designの発展 -
第4回
クラウド
Build 2019でKubernetesのサーバーレスフレームワーク「KEDA」発表 - この連載の一覧へ




