




GeForce GTX 2080は
Tiとは違うダイを採用か?
さて、問題はメインストリーム向けのGeForce GTX 2080である。これについては、同じくTU102を使うのか、それとももっとシェーダーを削減したダイなのか? という話題が飛び交っているが、筆者は別ダイ説を推したい。
というのは、クラスターを4つに減らし、かつ1クラスターあたり23SMとすると、ちょうど2944CUDAコア(4×23×32=2944)になるからだ。
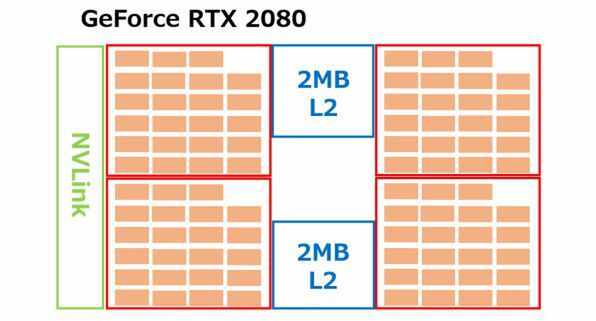
これにあわせてテクスチャーユニットは192ユニット(4×48)、ROPは80ユニット(256bit=32bit×8)としている。GeForce GTX 2080Tiもそうだが、なぜクラスターあたり24SMにしないかといえば、歩留まりの改善だろう。754mm2ものダイだから、当然多少は欠陥が出て当たり前である。
運よく欠陥がないダイはQuadroに、若干欠陥があるダイはGeForceに、と選別するのはごく自然な方針だし、その場合に24SMをフルに使うのは都合が悪い。22~23SM程度に留めておき、冗長コアで欠陥をカバーすることで歩留まりを上げると考えるべきだろう。
ところでなぜTU102ではなく別のダイ(これまでの命名法に則ればTU104になる)と思うかと思えば、さすがにTU102のダイは大きすぎで、原価が上がりすぎである。メインストリーム向けということを考えれば、ダイサイズをもう少し減らさないと厳しいものがある。
また、さらに下のGeForce RTX 2070を作ることを考えると、TU102のままでは厳しいと考えられる。ラフな試算だが、上図の構成のTU104は530mm2前後で製造できるはずだ。GP104の320mm2弱に比べるとだいぶ大型化しているが、RT Coreを突っ込みつつさらにCUDAの数を増やしている(のにプロセスは変わらない)のだから、これは致し方ないだろう。
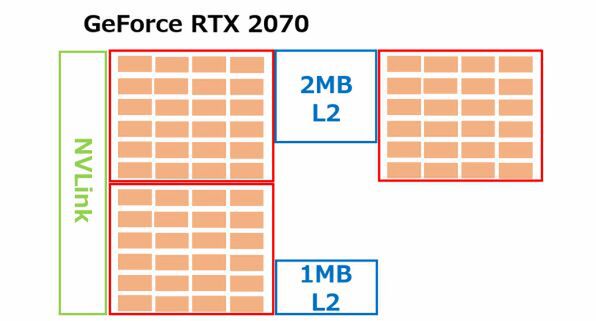
したがって、同じTU104を使うと予想されるGeForce RTX 2070の構成は下図のようになる。各クラスターごとに24SMのフル構成にする代わりに、1クラスターを丸々無効化すると想像され、これに応じて2次キャッシュも3MBに削減(4MBのうち1MB分を無効化)すると思われる。メモリーバスは192bitに減らされるが、クラスターが1個減ってるからちょうど帯域的にはマッチするだろう。
ちなみにNVLinkに関しては、NVIDIAがHotChipsで出した論文を見る限りTesla V100は6対のNVLink I/Fを持っているそうで、おそらくはTU102(Quadro RTX)も同じように6対のI/Fを持っていると考えられる。これはNVSwitchとの接続との互換性を取ると思われるためだ。
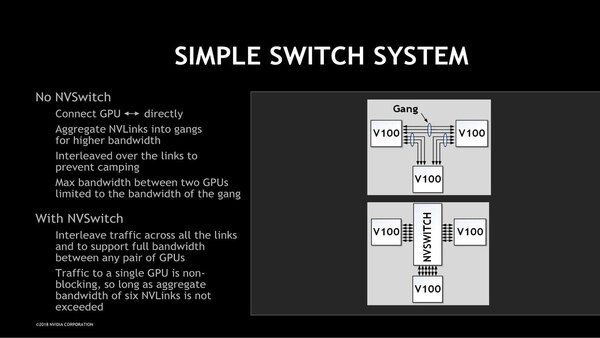
今年のHotChipsで説明されたNVSwitchの利用例。V100同士を3対づつでつなぐこともできるし、NVSwitchと6対でつなぐ(もしくは3つのNVSwitchと2対づつで繋ぐ)といったバリエーションがある
画像の出典は、HotChips 30におけるNVIDIAの“NVSWITCH AND DGX-2 NVLINK-SWITCHING CHIP AND SCALE-UP COMPUTE SERVER”
ただGeForce RTX 2080Tiは多くて3対程度だろう。4Way SLIを実現するにしても、各々が3対のLinkがあれば足りるからで、残りの3対は無効化されていると思われる。
TU104の場合は、物理的に3対分に減らされているだろう。そしてGeForce RTX 2070ではNVLinkそのものが無効化されているが、これは技術的というよりはマーケティング的な問題であろうと筆者は考えている。
さて、こうなるとより下のグレードのダイも当然あると思われる。要するにTU106にあたるもので、クラスターの数を2個、2次キャッシュは2MBまで減らした(そしてNVLinkは搭載しない)もので、メモリーもこのあたりになると安価なGDDR5を使うケースもあるだろう。
ただ、これが年内に出てくるかどうかは微妙なところだろう。Turingアーキテクチャーはレイトレーシングを利用するのが前提で、その場合には性能を発揮できるが、逆にレイトレーシングを必要としない古いゲームや負荷の軽いゲームでは、RT Coreは単なるお荷物となってしまう形だ(さらに言えばTensor Coreも使われない)。
NVIDIAは8月22日(米国時間)に“GeForce RTX: A Beast for Today’s Games - and Tomorrow’s”というブログエントリーを公開し、この中でGeForce GTX 1080 vs GeForce GTX 2080の性能比較を行なったがDLSSを使わないとおおむね3割~5割程度のフレームレート改善にとどまっている。
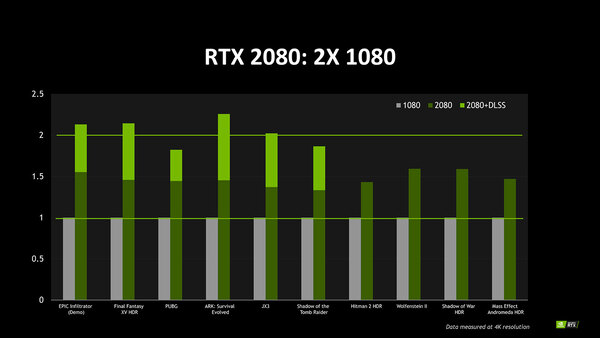
DLSSはDeep Learning Super-Samplingの略で、アンチエイリアスをDeep Learningベースで行なう(=Tensor Coreで処理をする)ことでSMの負荷を減らし、結果として描画性能を引き上げる技術
もちろんここにあるような負荷の高いゲームには効果がありそうだが、TU106のターゲットはメインストリームの下の方で、解像度も2K、HDRもなしといったあたりだろう。こうしたユーザーがレイトレーシングを必要とするのはまだ少し先であり、このあたりは様子を見ながらという感じではないかと思われる。したがって一応ロードマップ図には今年末としてTU106を入れてあるが、来年になっても不思議ではないだろう。

2016年~2018年のNVIDIA GPUロードマップ
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















