



紀伊國屋書店は約3000万件の統合マスタ管理で大きな導入効果
マルチバリュー型DB「ビッグデータロボ」はブラックな開発現場を変えられるのか?
2018年10月02日 09時00分更新

「ビッグデータロボ」と言ってもロボットではない。既存のRDBMSとも異なるマルチバリュー型と呼ばれるデータベースの製品名だ。高速、安価、開発者にうれしいビッグデータロボはブラックな開発現場を変えられるのか? 日本で製品を展開するビッグデータロボに話を聞いた。
性能、柔軟性、開発工数に課題を持った既存のRDBMS
市場のスピードにマッチしたデータ分析の価値が企業の競争力に直結する時代、既存のデータベースの限界が大きな課題となっている。
現在、多くの企業で用いられているSQL型のRDBMSは1つのデータを取り出すために、複数フィールドの結合処理が必要になり、パフォーマンスを上げるのが難しかった。たとえば、「誰がなにを購入したのか?」という購入フィールドを抽出しようとした場合、通常は顧客フィールドと商品フィールドを結合(Join)しなければならない。ビッグデータロボ 技術本部 部長の本田徹氏は、「性能を出すために高価なサーバーやストレージ機材が必要になり、インデックスやストアドプロシージャを別途設計しなければならない。そのため、全体のコストを押し上げることになります」と指摘する。
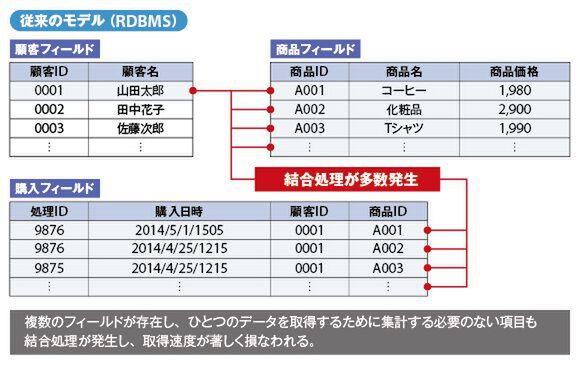
数多くのジョインで性能が劣化する既存のRDBMS
開発現場にとっても課題があった。注文書を作成するという単純な処理においても、既存のRDBMSの場合、注文テーブルや明細テーブル、担当者、顧客、商品など複数のマスタなどが必要になり、複雑なER図になる。さらにデータ取得時には、アプリケーション側で小計や税率計算などを行なうため、開発者はデータベースの構造をきちんと理解する必要があった。「今までのデータベース開発は、モデルを設計し、テーブルとER図を作り、あとは開発側にお任せというケースが多い。この場合、アプリケーション開発者がMVCアーキテクチャのView、Model、Controllerまですべてを担わなければなりません」と本田氏は指摘する。

ビッグデータロボ 技術本部 部長の本田徹氏
さらに既存のRDBMSでは、先にテーブルを定義してデータを流し込むため、後から変更するのは困難だ。変更するためにはデータベースの再設計・再構築が必要になり、コストや開発期間が増加する。総じて開発現場はブラックになり、予測不可能な市場のニーズに柔軟に対応することは難しくなる。
日本の現場ではデータベースがシステムに最適化されていない
こうした課題を解消する「ビッグデータロボ」は、既存のRDBMSと異なるマルチバリューモデルというデータ構造を持つマルチバリューDBになる。日本では開発元のフォーディーネットワークスからエイ・エス・シーが事業譲渡を受け、サービス名と同じビッグデータロボという社名で事業を展開している。
エイ・エス・シー システム部の舟山康夫氏は、「弊社は長らく大手SIerの受託開発を請け負ってきたのですが、自社でも新しい事業を始めようということで、まずはフォーディーネットワークスとの協業からスタート。今は事業譲渡を受けて、ビッグデータロボを日本で展開しています」と語る。

エイ・エス・シー システム部 統括部長 舟山康夫氏
マルチバリューモデルは、フィールド内に複数のバリューを保持できる2次元構造となっており、1つのレコードにすべてのデータを格納することができる。レコード数も無制限で、データも可変長。区切り文字で分離したレコードを詰めて格納するというシンプルな構造なので、データ量も小さく、あらかじめ空きを確保する必要もない。「たとえば、衣料品1つとっても、サイズや色、素材などさまざまな属性を持っています。こうした複数の属性を1つのレコードで管理できるので、用途は相当広いと思います」とビッグデータロボ 営業本部の吉田了二氏は語る。
マルチバリューモデルの場合、顧客フィールドに対して、複数の購入フィールドを格納できるため、顧客数分のレコード数にしかならない。商品アイテムや顧客が増え続けるECサイトでも、顧客の全購買履歴を1レコードで格納できる。当然、結合処理がきわめて少ないため、圧倒的に高速な検索を実現でき、ハードウェアコストも大幅に削減することが可能だ。
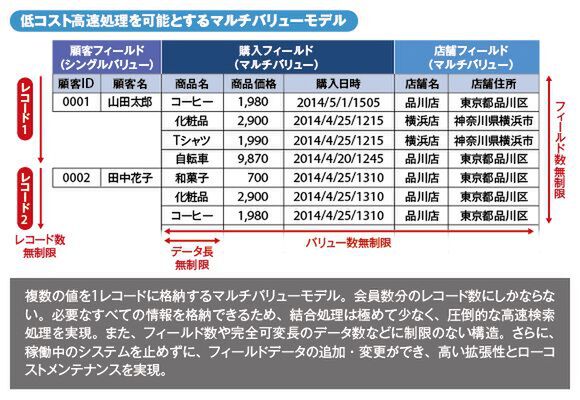
ビッグデータロボが採用するマルチバリューモデル
マルチバリューモデルの概念は1970年台から存在しており、OSのファイルシステムとして開発された「Pic OS」を始祖としてさまざまな製品が存在する。このうちビッグデータロボが採用するエンジンの製品は、米国では「Adabas」とともに市場をリードする製品として認知されている。
とはいえ、日本はマルチバリューDBの導入自体がほとんど進んでいない。既存のRDBMSと考え方が異なるため、エンジニアも少ない。そもそも大手SIerでマルチバリューDBをかついでいるところもないため、多分に市場や実績の問題に起因しているようだ。「本当はMongoDBのようなKey-Value DBでいいのに、無理してRDBMSを使っていることも多いですよね。日本では、データベースがシステムに最適化されていないのです」と本田氏は指摘する。
フィールドの追加も止めずに行なえる柔軟性が大きなメリット
ビッグデータロボは開発現場の課題も解消する。マルチバリューモデルを採用するビッグデータロボの場合、マスタのフィールドをあたかも実データのように扱える「仮想フィールド」を用いることで、ユーザーの要求仕様とテーブルを1対1で対応させることができる。アプリケーション開発者はあくまで注文テーブルのみを意識して実装を進めればOK。MVCアーキテクチャにおけるModelはもちろん、Controllerもサブルーチンとして包含されるため、開発者はスキーマ設計に依存せず、Viewのアクションに応じたインターフェイスの設計に専念できる。
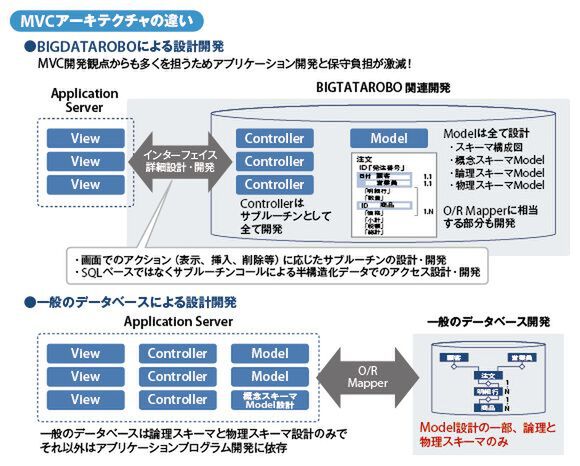
ビッグデータロボと既存RDBMSのMVCアーキテクチャの違い
シンプルなテーブル構造を持つビッグデータロボでは開発者のみならず、ユーザー側もテーブルに必要な項目が存在するかどうかチェックすることが可能になる。「お客様がExcelで持っている項目を縦に並べるイメージで設計ができます。要求仕様の通りにデータを持てるので、複雑なER図を見ながら、お客様もDB設計者も頭を悩ませるということが少なくなります」(吉田氏)。

ビッグデータロボ 営業本部の吉田了二氏
また、稼働中のシステムを止めず、フィールドデータの追加や変更ができるのも大きなメリット。テーブル定義(内部スキーマ)とディクショナリ(概念スキーマ)が分離しているので、ディクショナリを変更すれば、実データを触ることなく、フィールドの書き換え・追加・削除などが可能になる。「ディクショナリを経由して、内部スキーマを見ているので、簡単にテーブル定義の変更が可能です。ディクショナリも単なるファイルシステムなので、運用中も簡単に変えられます」(本田氏)。

実テーブルとディクショナリが分離しているため、アジャイル開発が可能
さまざまな特徴のあるビッグデータロボだが、開発現場に効く一番のメリットはこの柔軟性だ。「正直、検索性能を他社製品と比べても意味がないので、メリットは開発現場での柔軟性だと思います。アプリケーション側ではテーブル定義が変わりません。仕様が変わっても、ディクショナリを作り替えればいいからです。予測不能なシステムのニーズに対して、アジャイルに開発できるため、開発や運用のコストも大きく削減することが可能です」と本田氏はアピールする。
NoSQLとRDBMSのメリットをいいとこどりしたビッグデータロボ
マルチバリューDBのビッグデータロボは名前の通り、ビッグデータ処理に最適だ。もともとOSのファイルシステムとして開発された出自を持つため、写真や音声、動画、ファイルなどの非構造化データ、高頻度で更新されるセンサーデータなどあらゆるデータを取り込むことができる。
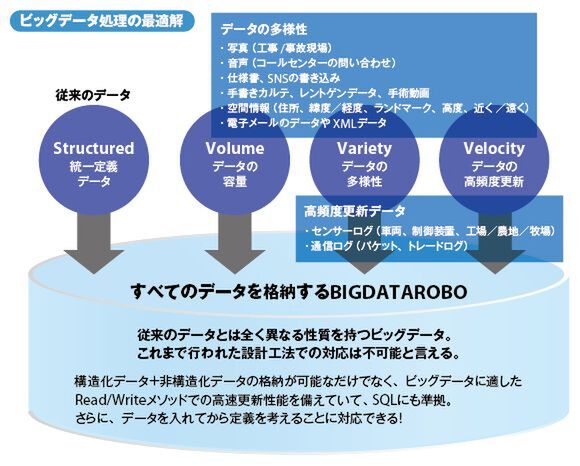
大量・多様・高更新なデータをすべて格納できるビッグデータロボ
一方で、既存のRDBMSで扱う構造化データも格納できるため、従来型システムの統合も可能だビッグデータロボの場合、SQLでのアクセスも可能で、C、Java、ODBC、JDBC、.NETなどさまざまな言語が利用できるほか、CやJava、Pythonなどを用いてディクショナリを経由しないデータへの直接アクセスすることも可能だ。
また、複数ユーザーの環境でもデータ更新を保証するトランザクション機構も可能で、ロックも共有レコード、更新レコード、共有ファイル、意図的ファイル、排他ファイルロックなど5種類を備えている。トランザクションに他のトランザクションを入れ込むネストも可能になっている。「今のシステムってデータベースを止まること前提で設計や運用を考えますが、ビッグデータロボは今のところ止まったことないです。だから運用や障害対応のために人を貼り付ける必要もありません」(本田氏)とのことで、高い可用性を実現しているのも大きなメリットだ。
基幹系システム、データ分析、システム統合などさまざまな用途に利用できるビッグデータロボ。舟山氏は「システムを止めないとなにもできないという既存のRDBMSとは違い、ビッグデータロボであれば、システムを止めないでフィールド追加や削除が可能です。ファイルシステムそのもののなので、バックアップも容易です」と現場エンジニアに向けたメリットを強調する。
ビッグデータロボの活用で約3000万件の統合マスタの管理を実現した紀伊國屋書店
こうしたビッグデータロボを2013年に導入し、約3000万件におよぶ統合マスタを構築したのが大手書店チェーンの紀伊國屋書店だ。マルチバリューDBの強みを知り尽くした同社がビッグデータロボにリプレースした背景や性能面でのメリットを情報システム部 店売システムグループリーダー 部長 藤井裕之氏、グループ次長 伊奈 宏氏に聞いた。

増え続ける商品の統合マスタをマルチバリューDBで長らく管理
紀伊國屋書店は1980年台のホスト時代から一貫してマルチバリューDBを用いてきた。まずは店舗の購入履歴であるPOSのデータベースからスタートし、今では版元(出版社)や取次(卸)からのデータを登録した商品管理マスタをマルチバリューDBで構築している。「それ以前は、店頭の在庫を調べようにも、完全に店員の頭の中にあるデータベースに依存していました。でも、商品数が増え、売り場面積が拡大すると、店員も商品知識をカバーできなくなります。そんな中、お客様の要望に応えられるようにするには、在庫や棚の管理が必要になってきたんです」(藤井氏)。

紀伊國屋書店 情報システム部 店売システムグループリーダー 部長 藤井裕之氏
トータル3000万件に及ぶデータベースは、出版社からの提供を受けてどんどん拡大していき、データが減ることはないという。しかも、書名や説明文が入るので、データ自体が長い。「特に学術系の専門書の場合は、入手不可能でもきちんと検索できるようにしてほしいという要望が強いんです。絶版したものを古書や電子書籍として販売することもありますので、基本的に削除されません」と藤井氏は語る。
こうして拡大を続けるデータベースをいかに運用していくか、そしてレスポンスよく検索できるようにするか。長らくマルチバリューDBを用いてきたのも、こうした課題を解消できる唯一の選択肢だったからだ。「当時、全文検索が遅かったので、書籍データからキーワードを抽出し、マルチバリューDBで管理するようにしました。1つの項目に対して検索するだけで、マルチバリューのいずれかの項目に当たって、必要なものを引き出せます。複合キーワード検索なので、パフォーマンスもよいです」と藤井氏は語る。
社内システム向けだったマスタDBの利用用途もこの20年でどんどん拡大してきた。たとえば、POSデータは売れ筋情報などを見るための「紀伊國屋PUBLINE」として出版社に提供されているし、在庫データは取次会社にも公開している。また、Amazon.comとほぼ同時期にスタートしたECサイト「紀伊國屋ウェブストア(旧:Book Web)」の在庫データベースとしても利用されている。
2代目のマルチバリューDBとして導入されたビッグデータロボ
そんな紀伊國屋書店が長らく利用してきたマルチバリューDBをリプレースすることにしたのは、ポータル、ポイント管理、書籍購入、DVD・CD購入などの分割された複数のサーバーを統合するのが目的だ。そして、開発元の戦略変更で製品の継続的な利用が危ぶまれたのがきっかけに、ECパッケージのDBとして新たに導入されたのが同じマルチバリューDBのビッグデータロボ(旧称:4D DAM)になる。
紀伊國屋書店では、マルチバリューDBからRDBMSへの移行という選択肢は基本的になかったという。「レスポンスや性能、データベースの統合のしやすさなどマルチバリューDBでさまざまなメリットを得ていました。正直、マルチバリューDBに慣れすぎていて、既存のRDBMSの正規化みたいな文化に全然慣れないんです。複数のテーブルで構成されているRDBMSに移行するのは、とても面倒くさいというイメージがありました」とのことで、既存のマルチバリューDBの定義をそのまま使えるというのがビッグデータロボの大きなメリットだった。

紀伊國屋書店 情報システム部 店売システム グループ次長 伊奈 宏氏
導入前の性能テストでは、約250万件の棚卸し処理を行なったが、他社製品で45分かかっていた処理が、ビッグデータロボは1分40秒で完了。商用のUNIXサーバーを用いる競合に対し、汎用のPCサーバーとWindows Serverを用いるビッグデータロボはコスト面も安価で、選定理由は基本的に明確だった。
とはいえ、要件定義に時間がかかり、ハードウェアも入れ替えたため、最終的には移行に2年近くかかった。「従来のマルチバリューDBはインデックスをたくさん作ってもあまり性能も落ちなかったのですが、ビッグデータロボの場合は更新に時間がかかってしまいます。なるべくインデックスを作らないよう設計しなければならないので、従来に比べると設計は難しいです」と伊奈氏は振り返る。
それでも、導入メリットは大きかった。店舗での購入履歴をWebストアからも参照できるようになり、マーケティング施策も迅速になった。「お客様用のDMを打つのに当たって、購入履歴からさまざまな条件で宛先を抽出するのですが、従来はバッチ処理が必要した。でも、ビッグデータロボではこれがほぼリアルタイムでできるようになりました」と藤井氏は語る。
また、ビッグデータロボの仮想フィールドの機能を用いることで、複数テーブルの串刺し検索も可能になった。「データベースをチューニングしなくとも、高いパフォーマンスを実現できています。会員情報と購買情報という2つのテーブルにまたがった検索をレスポンスよく実現できるようになりました」と伊奈氏は振り返る。近々、保守切れしたハードウェアをリプレースする予定で、より高速化することを期待しているという。
このほか、ビッグデータロボは日本でも確実に事例を重ねており、3年かかった開発期間を10ヶ月に短縮した大手証券取引所のほか、既存のRDBMSの10倍の更新性能を実現した金融情報データ配信システム、5日間かかっていた不具合の抽出を14秒にまで短縮した製造業、移動平均法による原価計算導入を既存の1/50のコストで実現したスーパーなど、さまざまな事例を持っている。既存のRDBMS開発に限界を感じるユーザーは、ぜひWebサイトをチェックしてもらいたい。
(提供:ビッグデータロボ)




