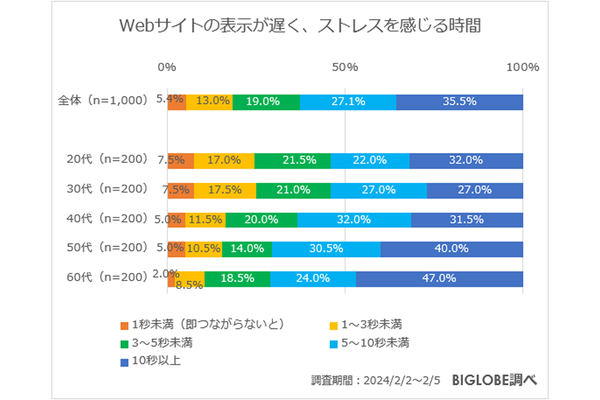
人間同士の罵倒を避けるため、1万3500件のWikipediaのノートページのデータが、機械学習用の訓練データになった。英語なので、日本版を作れば、ののしり合いを機械が仲裁してくれるかもしれない。
女性蔑視や人種差別、罵倒など、ネット上で個人を攻撃している投稿1万3500件以上のコレクションが完成した。
ウィキペディアのノートページから収集された悪口を、アルファベット(グーグルの親会社)とウィキメディア財団(ウィキペディアを運営する非営利団体)の研究者が10万件以上の温和な投稿とともにデータ集として公開したのだ。研究者によると、このデータは、ネット上の迷惑行為を理解して取り締まるソフトウェアを訓練する研究に役立つという。
ジグソー(言論の自由や汚職との戦いを理念に掲げるアルファベットの子会社)のルーカス・ディクソン主任研究科学者は「最も議論が激しく、最も重要な話題について、人々がインターネット全体で生産的に議論できるために弊社ができることを理解するのが目標です」という。
ジグソーとウィキメディア財団の研究者は、クラウド・ソーシングサービスにより、ウィキペディアのノートページに投稿された11万5000件以上のメッセージを人々に確認してもらい、ウィキぺディアの規則が定める個人攻撃に当たるかどうかを判定した。共同研究者はすでに同じデータを使って機械学習アルゴリズムを訓練し、個人攻撃の判定でクラウド・ソーシングの作業者に匹敵する精度を達成した。なお、ウィキペディアの編集者による6300万件の議論に関する投稿全てをアルゴリズムに処理させたところ、モデレーターが議論を整理している場合に個人攻撃が発生したのはわずが10分の1程度だとわかった。
ウィキメディア財団は昨年、ウィキペディア内の迷惑行為の減少を優先事項として掲げた。この方針は、ウィキペディア・コミュニティのとげとげしい官僚的な雰囲気を和らげる現在の活動の強化策だ。ウィキペディアのこうした雰囲気のせいで、新たな投稿者の参入が阻まれていることがわかっている。ウィキペディアは編集者数が減少しており、また、男性や西洋出身者を中心とするサイトに、多様性のある新参加者が加わりにくくなっており、迷惑行為やウィキペディアの雰囲気の問題を研究すれば、原因を理解できるだろう(“The Decline of Wikipedia”参照)。
ネットいじめの研究や、ネットいじめを特定して対処可能なソフトウェアの開発を目指したのはジグソーやウィキメディア財団が最初ではない。しかし、ウィキメディア財団でデータサイエンスを研究しているエルリー・ウルチェンによると、迷惑な投稿かどうかを判定するためにコメントを分類して収集した(分類されたコメントは機械学習ソフトウェアの学習に必須だ)のは珍しいという。
正確にデータを検索する方法を機械学習アルゴリズムが学習するためには膨大な量の分類された実例が必要だ。今回収集されたウィキペディア上の個人攻撃やコメントのコレクションは、これまで利用可能だったデータの集まりの10倍から100倍以上の量だとウルチェンは推定している。
しかしソフトウェアは言語の全てのニュアンスを理解するまでには至っておらず、ネットいじめを特定するように訓練されたアルゴリズムが、実際のモデレーターと同じように判定できるかは不明だ。ウィキメディアのウルジンによると、ソフトウェアによる検知を避けるために悪口の表現を変える人も出てくるかもしれない。「人間と敵対するように機械が干渉した時、何が起こるかはわからないのです」