ディープラーニングによっていよいよ実現に向かうコンピューターとの会話
マイクロソフトが世界最高レベルの音声認識技術、単語認識誤り率6.3%を達成
2016年09月20日 19時06分更新

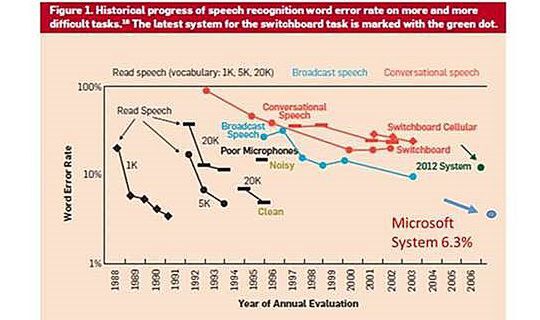
これまでの音声認識技術の進歩とエラーレートの低下(縦軸は対数)
マイクロソフトは9月13日、同社ブログにて音声認識の精度は世界最高レベルのエラーレート6.3%を達成したと発表した。
これは9月8日~12日開催された国際的カンファレンスInterspeech2016で発表されたもの、最新の音響モデル技術を用いることにより、業界標準ベンチマークテスト「NIST 2000」において単語認識誤り率6.3%を達成。前回に記録を更新したIBMのチームの認識誤り率(6.9%)を更新する成績を上げたという。
音声認識技術は近年になって急速に進歩を遂げており、1995年には誤り率は43%を超えていたものが2004年には15%まで下がった。ニューラルネットや機械学習の研究が進んで適用されたことが大きいが、マイクロソフトではディープラーニングのトレーニングをより高速・高精度に最適化できることが大きな重要なポイントだという。
とくに近年になって大きく貢献しているのはGPU。本来はグラフィック用プロセッサながら、強力な並列演算機能は機械学習などの処理に適しており、認識エンジンのトレーニングを高速に処理できるため、研究の試行錯誤もすみやかに進めることができる。マイクロソフトではSkype翻訳やコルタナなどで音声認識を実用化しているが、誤り率10%以下という精度はほぼ人間に近いところあり、今後ホームユースや車載など広い用途での普及が見込まれる。









