




1キャビネット以内の構成では性能を発揮
Cellを構成するプロセッサーそのものは40bitのアドレス空間を持つ(KSR-2では64bitになった)。さすがに1088個ものCellがアドレス空間を共用すると、連続的にアドレスをマッピングしたとしてもCellの識別だけで11bit必要だ。
一方、ローカルキャッシュの32MBには25bit必要なので、最低でも36bitアドレスが必要になる。この時点で汎用のプロセッサーでは足りない(ほとんどが32bitアドレス)ことになる。なので、チップそのものはKSR製の独自のものである。
内部は4つのブロックに分かれており、以下で構成される。
| CEU(Cell Execution Unit) | 命令の解釈や一部の実行を行なう。 |
|---|---|
| XIU(I/O Processor) | 名前の通りI/O処理を行なう。 |
| IPU(Integer Processing Unit) | 整数演算を行なう。 |
| FPU(Floating Point Unit) | 浮動小数点演算を行なう。 |
ちなみに英国のeBayにこのKSR-1のチップだけが出品されているのだが、チップそのものは6種類(3-1333-01~3-1138-01)ある。

KSR-1のボード写真。この1枚のボードにコンピュートノード×2が搭載されている。出典はWikipedia(https://en.wikipedia.org/wiki/File:Ksr_cell_top.jpg)
KSR-1のボード写真を見ると1コンピュートノードあたりこれらのチップを合計で12個利用している。内訳は下記のとおり。
| チップ名 | 個数 |
|---|---|
| 3-1333 | 1個 |
| 3-1334 | 1個 |
| 3-1335 | 1個 |
| 3-1336 | 1個 |
| 3-1337 | 4個 |
| 3-1338 | 4個 |
おそらく基板で右下にある3-1333~3-1336がCEU/XIU/IPU/FPUで、その左脇にあるSRAM×8がサブキャッシュ(合計512KB)、上段の8つのチップは32MBのローカルカッシュで、その周りにあるものがローカルキャッシュ用のTag RAMではないかと思うのだが、確証はない。
命令セットは2命令同時実行のVILWであり、CEU/XIU向けの命令×1とIPU/FPU向けの命令×1を同時に実行できる。FPUは1サイクルあたり最大2つの計算が可能(乗加算命令を同時に実行可能だった模様)となっている。
なお、動作周波数そのものは20MHzで、このためCellあたりの最大性能は40MFLOPSという計算になる。ちなみにKSR-1はシャープの1.2μm CMOSプロセスで製造された。
超並列でしかもALLCACHEアーキテクチャーという尖った構成だけに、プログラミングはさぞ難しかろうという気もするのだが、少なくともKSRはこの点に関してかなり努力はした。
C/C++に加え、Micro Focus COBOL(Micro Focusは1976年以来ずっとCOBOLを提供し続けてきているベンダーで、現在も存在する)、Oracle PRDBMS、ADBのMATISSE OODBMS(オブジェクト指向データベース)などが提供されており、またOSとしてはUNIXベース(OSF/1の派生型:Machカーネルベースという説明もあった)が提供された。
さて、最初の製品は1991年9月にオークリッジ国立研究所に納入された。当初は32cellの構成(つまりRing 0が1個だけ)で、翌1992年にはこれが64cellの構成になった。
下の画像がその構造だが、Photo02のボードを2枚(つまり4cell)収めたキャビネット×8が1つのラックに収められているようだ。
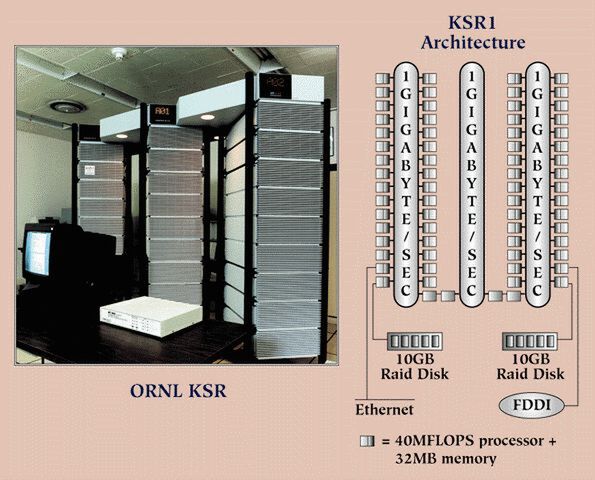
出展はオークリッジ国立研究所がSC98で示した展示資料(http://www.csm.ornl.gov/SC98/timetab.html)の写真(http://www.csm.ornl.gov/SC98/ksr.gif)。構造を見る限り、中央のキャビネットにはcellは入っていないようだ
キャビネットは9個あるが、上の画像にもあるようにRAID DISKやFDDI/EthernetなどのI/F部を収めるのに別のキャビネットが必要だったと思われる。
それぞれのラック内のキャビネットに収められたCellは1GB/秒のRing 0で接続され、キャビネット間は上の画像でラック上端間をつなぐ白い構造内に収められたRing 1でつながっていると思われる。
オークリッジ国立研究所からは、この初期(32cell)構成での評価レポート(Kendall Square Multiprocessor Early Experiences and Performance)が1994年に公表されている。
これによればCRAY用に記述された高温超伝導物質のエネルギー密度のシミュレーション用プログラム(Fortranで17000行)の移植はそれほど難しくなく、32cell構成で243MFLOPSの性能を実現できたとしている。
またデータベースについても、KSR製のQuery DecomposerというソフトウェアとOracleを組み合わせることで、16cellまでの構成で効率93%(14.88倍速)が実現できたという論文もある。
ただその一方で、先のRamachandran氏の論文では取り扱うデータ構造が大きくなると、32MBのローカルキャッシュは容量が小さすぎ、またRing 0を超えてRing 1経由でのアクセスになったとたんにネットワークがボトルネックになって性能が上がらないとしている。
とりあえず1キャビネット以内の構成ではそれなりの性能が出るが、それを超える場合にはやや工夫が必要、という評価だった。
→次のページヘ続く (粉飾決済が発覚して倒産)
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















