




性能が出ればCPUはなんでもいい!
外部の汎用CPU「Alpha EV4」を採用
肝心のProcessor Elementであるが、1つのProcessing Element Nodeは2つのProcessing Elementから構成される。
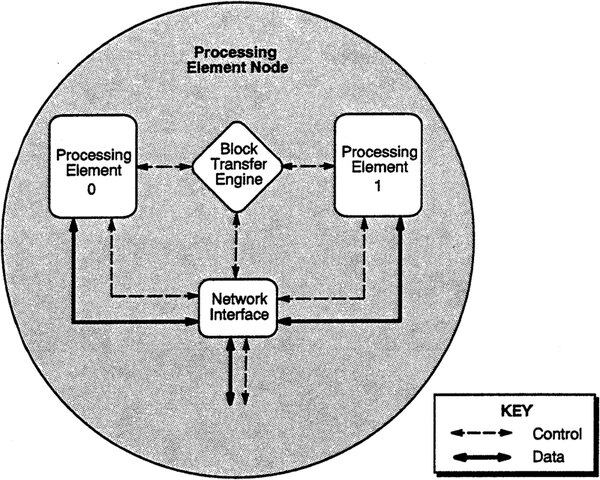
この“Block Trasfer Engine”と“Network Interface”はCRIが独自に設計、製造した
個々のProcessing Elementは、CRIとしては初めて外部の汎用CPUを使うことにした。搭載されたのはDECの150MHz駆動のAlpha EV4こと21064である。
ここでCRIが外部から購入した理由もまた公式には明らかにされていないが、想像はたやすい。というのは、スクラッチから「超並列に向いた」CPUを作るとなると、さらに数年の開発期間がかかる。
CRIはベクトルプロセッサーに関しては豊富な実績とノウハウを持っているが、スカラープロセッサーに関しては(もちろんCRAY-1以来実装はされているものの)それほど知見があるわけはなかった。
さらに、まだこの時点では「超並列に適したプロセッサー」なるもののアーキテクチャーとはどんなものかに関しても理論が固まっていたわけではない。
インテルは80386やi860でそのままトーラスを構成したし、nCubeは独自とはいえ、プロセッサー部はごく普通の構成だ。コネクションマシーンは超並列の極北ともいえる1bitプロセッサーの集合体の構造だが、CM-2では32bit FPUノードを追加、CM-5ではSPARCを使ったりしているため、アーキテクチャー的には迷走しているとも言えなくもない。
そもそものT3Dの目的が超並列のアーキテクチャーの実装(特にソフトウェア面での対応)が主であり、プロセッサーそのものは極端な話、入手性が良く性能が出て実装密度が上げられるものだったらなんでもよかったと思われる。
汎用CPUのAlpha EV4は、以前ASCI Qの回で説明したが、浮動小数点演算性能はそう悪くなく、あとは適切なOSやコンパイラが用意されればそれなりの性能が発揮できると期待された。
実装は、下の画像のように2 PE Node(つまり4PE)が1枚のボードの上に実装される構造になっていた。
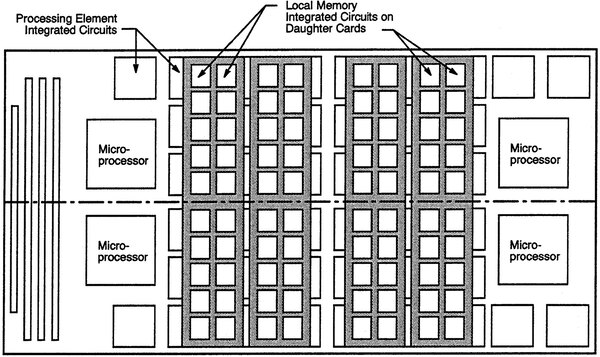
ボード写真が見つからなかったのだが、150MHzのAlpha EV4のTDPは21Wほどで、それなりに大きなヒートシンクが搭載され、メモリー用のドーターカードはこれを避ける位置に配されたものと思われる
DRAMは下の画像のように、ボードの上にドーターカードを装着、ここに実装という仕組みである。
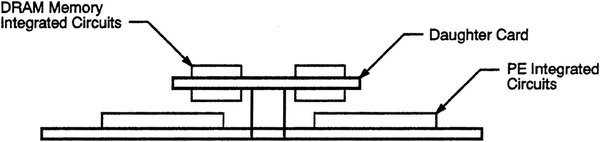
ドーターカードの構造。文献を読む限りはSIMM/DIMMなどは使われず、ドーターカードに直接DRAMが配置されていた模様。容量はドーターカード1組あたり、4Mbit DRAMの場合で2MB、16Mbit DRAMの場合で8MBとなっており、1つのプロセッサーあたり4MBないし16MBが利用可能となる
ところで先ほど3DトーラスでZ軸が2ノードしかないと述べたが、どうもT3Dの場合、Z軸方向のリンクはこのボードの上で完結していて外に出ない構造になっているように思える。
拡張性を無視すれば確かにこの実装はボード間配線も減らせるし良いアイディアであるが、ある程度ノード数が増えると通信のHop数が増えることになり、むしろ性能面ではネガティブになりかねない。最初の試みだから、そのあたりは控えめに実装を考えたのかもしれない。
ちなみにOSは、それまでCRAYで利用されていたUNICOSとは異なる、MicrokernelベースのものをUNICOS MAXという名前で実装した。
これは本当にタスクスケジューリングその他の機能しかないもので、フロントエンドにCRAYのC90などのマシンを用意し、ここがプログラムのロードやI/O処理などをつかさどる格好になった。その意味では、CRAY T3Dは巨大な超並列方式のアクセラレーターと言えなくもない。
このCRAY T3Dは1993年9月2日にプロトタイプがピッツバーグスーパーコンピュータセンターに納入された。この時点ではわずかに16PE Nodes(32プロセッサー)構成のものだが、19994年の初めには256PE Nodes(512プロセッサー)構成にアップグレードされ、ピーク性能で75GFLOPSを発揮することが期待された。
もっともこの納入の時のプレスリリースを見ると、同時にPSCはCRIとの間でソフトウェアの共同開発を行なう契約を結んだ、という話が出てきているあたり、ボトルネックがソフトウェアにあった事は明白である。
実際TOP500のスコアを見ると、EPFL(Ecole Polytechnique Federale de Lausanne:スイス連邦工科大学ローザンヌ校)に納入された128PE NodesのCRAY T3D MC256-8が理論性能38.40GFLOPSに対して実効性能は25.30GFLOPSである。
ピッツバーグスーパーコンピュータセンターの256 PE NodesのCRAY T3D MC512-8が理論性能76.80GFLOPSに対して実効性能50.80GFLOPSということで、効率は65~66%というあたりであまり褒められた数字ではない。とはいえ、ここで得た経験は次のT3Eに生かされることになった。
→次のページヘ続く (使える超並列マシン「CRAY T3E」)
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ







































