




倍精度浮動小数点演算ができるCell
それが「PowerXCell 8i」
「PowerXCell 8i」とは、65nm Cellの倍精度浮動小数点演算拡張版である。先にSPEは1つあたり25.6GFLOPSという数字を記したが、これは単精度の場合で、倍精度では1.8GFLOPSでしかなかった。
要するに単精度浮動小数点演算しか考慮していないので、倍精度だと極端に性能が落ちる。これでは科学技術計算には使えない。そこで倍精度の浮動小数点演算能力を強化したのが、PowerXCell 8iである。

「PowerXCell 8i」の概要。出典は“PowerXCellと線形計算”(日本IBMの霜田善道氏)より。eDPとX2D/DDR2コントローラーのため、全体のコアサイズが一回り大きくなった
通常のCellとの相違点は2つある。
- それぞれのSPEに、新たにeDP(enhanced Double Precision)ユニットを追加し、倍精度浮動小数点演算でSPE1個あたり12.8GFLOPSの演算を可能にした。
- メモリーコントローラーの先にX2D(XIO to DDR2)ブリッジを追加し、DDR2メモリーコントローラーを搭載した。
2点目は、元々のCellはご存知の通りXDR DRAMを搭載する。これは帯域こそ25.6GB/秒と高速なものの、メモリー容量は(XDR DRAMに限れば)256MBしかなく、さすがにこれは科学技術計算には不十分である。
かといってXDR DRAMのまま容量の増加は難しい。大容量のXDR DRAMは存在しないし、XDR DRAMの構成上メモリーの拡張性が限られたからだ。
そこでXDR DRAM用のXIOというI/Fに、DDR2とのプロトコル変換を行なうX2Dというブリッジを経由してDDR2 DIMMを装着できるようにした。転送性能こそやや下がるものの、搭載できるメモリー容量を大幅に増やすことが可能になった(理論上チップあたり16GB)。
このPowerXCell 8iを2つ搭載したブレードが「QS22」と呼ばれる。IBMは単体での利用に備えて、PowerXCell 8i周辺に豊富な回路を実装したが、RoarRunnerでは周辺回路はほとんど利用されず、またDIMM容量もPowerXCell 8i1つあたり4GBになっている。
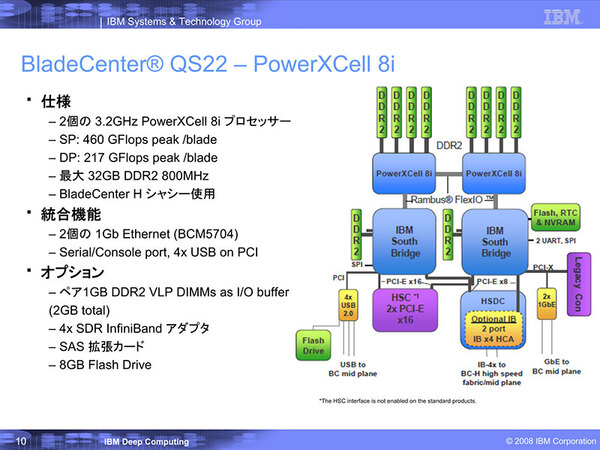
「QS22」の概要。こちらから直接Infiniband HBAを出したり、GbEで接続したりということも可能な構成だ
内部は下の写真のようになっている。RoadRunnerでは3種類4つのブレードをまとめて1ノードとした。

「QS22」の写真。中央の銅のヒートシンクの下にPowerXCell 8iが鎮座する。以下の出典は“Roadrunner: Hardware and Software Overview”(IBM Redbook)より
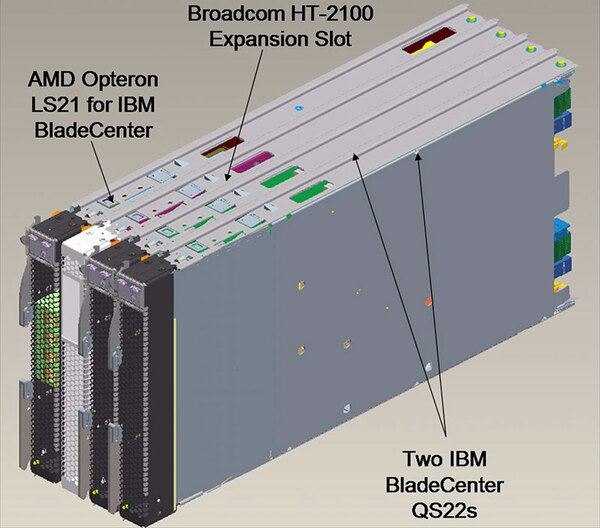
RoadRunnerでは3種類4つのブレードをまとめて1ノードとし、IBMはこれを「TriBlade」と称した
ノードあたりの性能は、PowerXCell 8iのSPEだけを使った場合で409.6GFLOPS、PPEも参加させると435.2GFLOPSになる。さらにOpteronにも仮に計算をやらせたとすると理論上は14.4GFLOPSほどの上乗せにはなるが、さすがにここまで使い切るケースはなかったようだ。
PPEコアも計算に割り当てるとSPEコアの制御が間に合わないうえ、プログラミングが面倒ということもあり、もっぱらSPEでひたすら計算し、PPEはSPEの制御、Opteronはデータの入出力などに専念した形だ。
一応1つのOpteronのコアと1つのPowerXCell 8iが対になり、またメモリーもコアあたり4GBに揃えられたのは、このあたりをプログラミングから簡単に扱えるようにしようという配慮と思われる。
ラック1本には、このTriBladeが12組入り、これ1本で4915.2GFLOPSと約5TFLOPSであるから、これを200本並べれば1PFLOPSである。
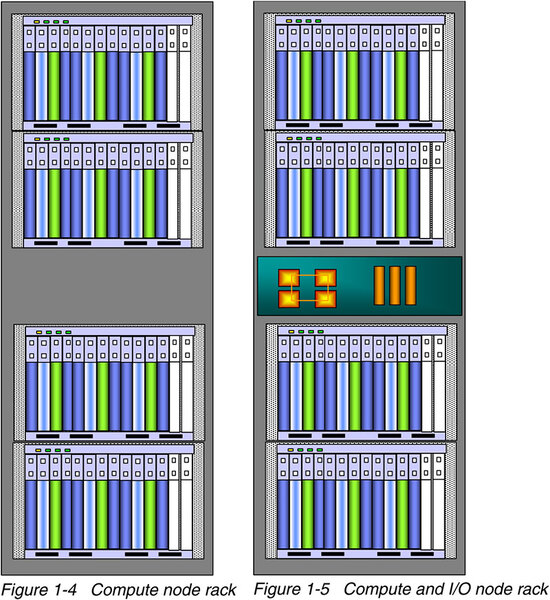
ラックの構造。白いブレードは未使用スロットと思われる
実際には、Compute RackとI/O+Compute Rack、それとSwitch&Service Rackの16本で、1つのConnection Unitと呼ばれるグループを形成した。
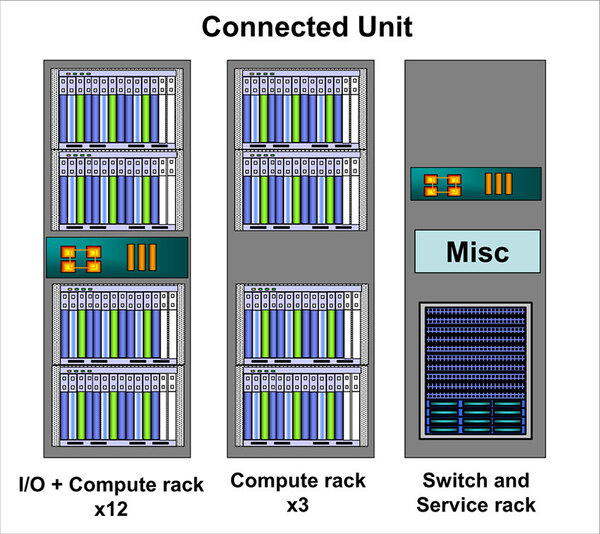
Connection Unitの構成。I/OにはIBMのX3655が利用された。これはOpteron 2218をデュアルで搭載するブレードで、RAIOコントローラーなども搭載する
1つのConnection Unitには都合180個のTriBlade(=ノード)が装備されたので、Connection Unitあたり73.7TFLOPSほどになる。
この1つのクラスターあたり1つの288ポートInfiniband Switchが搭載され、Connection Unit内のノードは1hopで他のノードと接続される。ちなみに288ポートのうち180ポートは直接各ノードに、12はI/Oノードにつながり、残りの96ポートが上位のスイッチに接続される。
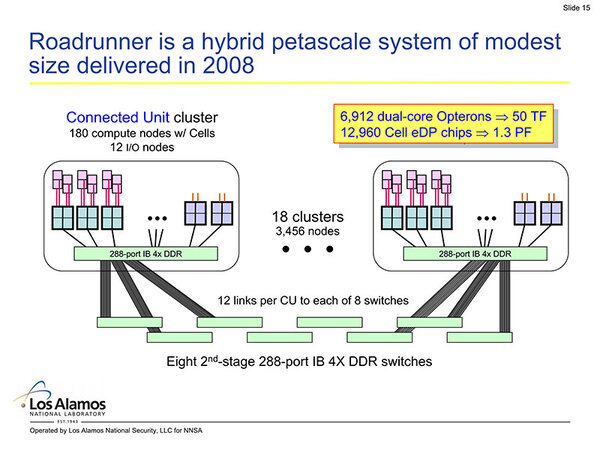
これはRoadrunner Technical ManagerのKen Koch氏による論文“Sweep3D (Sn transport) & other key Roadrunner applications”からの抜粋。ノード数が多いのはI/Oノードも含めているため。(180 TriBlade+12 I/O)×18=3456となる
Infinibandそのものはx4 DDRなので、信号速度自体は20Gbpsになるが、Embedded Clockを使っているため実質的なデータ転送速度は16Gbpsになる。
Connection Unitは全部で18あり、このConnection Unit同士は8台のInfiniband Switchで相互接続されるが、それぞれのConnection UnitとSwitchの間は12リンクで接続されるというFat Tree構成となっている。ピーク性能では1.3PFLOPSを超えるシステムがこれで出来上がった形だ。
実効性能で1PFLOPS超えを果たす
システムは2008年5月、ニューヨークにあるIBMの工場でフルシステムで組み上げられ、その後ニューメキシコにあるロスアラモス国立研究所に夏ごろに納入された。この工場で組み上げられた時点で、実効性能で1PFLOPS超えを果たし、2008年6月のTOP500ではBlueGene/Lを打ち破ってNo.1にランクインしている。
ロスアラモス国立研究所に納入後は、若干性能改善を果たして、2009年6月までTOP500での1位の座を守り続けた。
その後はやや構成を変えた状態で運用されたようだが、2012年11月の時点でもまだ22位に入っているあたりは、絶対性能としてはかなり強力なマシンだったことは間違いない。
効率は、理論性能の1375.8TFLOPSに対して実効性能1042.0TFLOPSで76%弱なのでそう悪くはない。1042TFLOPSに対して消費電力は2345KWだったから、性能/消費電力比は444.3KFLOPS/Wとなり、こちらも抜群に良い数字であった。
とはいえ、この後に登場したHPCマシンはさらに性能/消費電力比を改善したために、RoadRunnerの消費電力は過大とみなされるようになってきた。
実際、2012年11月のTOP500を見ると、RoadRunnerに次ぐ23位のマシンであるエジンバラ大学に置かれたBlueGene/QベースのDiRACは、1035.3TFLOPSをわずか493KWで実現している。結局この消費電力がネックになり、2013年3月末を持ってRoadRunnerの稼動は終了した。
ちなみにIBMはこのPowerXCell 8iを拡張した、ワンチップでTFLOPSを実現できるCPUを引き続き開発していた。具体的にはPPE×2+SPE×32の「PowerXCell 32ii」、それとPPE×4+SPE×32の「PowerXCell 32iv」であるが、最終的にこれらのプロセッサーは世に出ることなく消えてしまった。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ



































