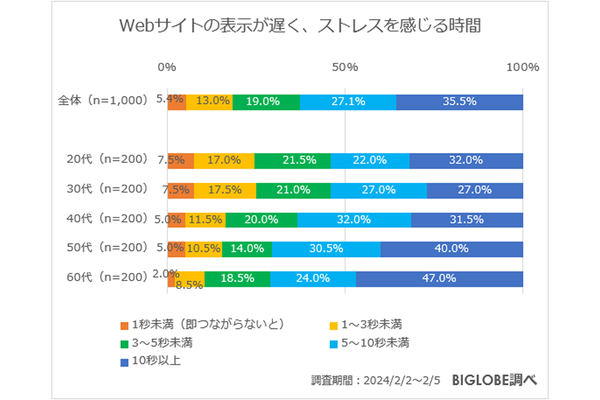
METAタグ活用完全ガイド noindex nofollow noarchive unavailable_after など使い方まとめ
2015年01月08日 12時18分更新
記事提供:SEMリサーチ

検索エンジンのクローラの動作や行動を制御するためのロボット排除プロトコル(REP、Robots Exclusion Protocol)の中でも、robot meta タグを用いた方法の紹介です。2015年1月1日時点でサポートされているものを紹介しています。 nositelinkssearchbox などSEO担当者に関連するMETA要素も含んでいます。
以下、基本的な知識と、noindex, nofollow, nositelinkssearchbox, notranslate, noarchive, nocache, nosnippet, noimageindex, noodp, unavailable_after について個々のMETAタグの機能と役割に加えて、適宜注意事項も記載しています。
robot METAタグを記述しない時はクローラを許可する意味に
Webページに robots METAタグ記述が存在しない場合、クローラは対象ウェブページを普通に巡回し、外部へのリンクも辿り、キャッシュもします。つまり index,follow と書くのと同じ意味となります。
例)
<meta name="robots" content="index,follow">
(全てのクローラに対して、インデックスとリンク巡回を許可する)
index,follow がデフォルトのクローラ挙動になります。従って、もし特に制限を設けるつもりがないならば、何も記述する必要はありません。書いても書かなくても同じ意味のディレクティブとして働きます。
name属性に検索エンジンを指定する
meta name=のところに robots と書いた場合は、全てのクローラが content= で指定されたディレクティブ(指示)に従います。googlebot と記述すると、Googleクローラのみがディレクティブに従います。
例)
<meta name="robots" content="noindex,nofollow">
(全てのクローラに対して、インデックスしない、リンクを辿らないように指示)
<meta name="googlebot" content="noindex,follow">
(googlebot に対して、インデックスは許可しないがリンクを辿らせるように指示)
noindex:検索結果で対象ページを非表示にする
noindex は、対象ウェブページを検索結果で非表示にします。厳密に説明すると、「クローラは対象ウェブページを巡回して、インデックス(データベース)に格納するが、検索結果には表示しないようにする」という意味になります。
つまり noindex は文字通り「非表示」にするだけでクロール自体はされます。もしクロール自体を拒否したい場合は、robots.txt で disallow (クロール拒否)の指示を行わなければなりません。
例1) 全てのクローラに noindex を指示
<meta name="robots" content="noindex">
(全てのクローラに対して、対象ページを検索結果に表示しないように指示)
例2) Googlebot に noindex を指示
<meta name="googlebot" content="noindex">
noindex の robots meta タグは次のようなケースで役立ちます。
- キャンペーンページへの誘導を制限したい:例えばメールマガジン購読者向けに特別に用意した割引クーポンを提供するためのページを準備し、そのURLをメルマガで告知した場合などが該当します。あくまでメルマガ購読者向けに用意した特別ページであって、検索エンジン経由でそのページを発見してほしくはないでしょう。こうした場合、対象キャンペーンページに noindex ディレクティブを記述することで、検索経由の来訪者を制限できます。
- 低品質なページを検索結果に反映させたくない:ヒット件数がゼロ件のサイト内検索結果ページや、サイト内に点在する重複コンテンツの1つに過ぎないページ、来訪者の回遊に何ら意味のないアーカイブやカテゴリページといった、検索結果に表示するには不適当と考えられるページに対して noindex を付与します。パンダアップデート対策にも有効です。
- 特定利用者の為に用意されたページ:例えば B2B/C サイトで「一般ユーザー向けのログインページ」「SOHO・個人事業主のログインページ」「法人向けログインページ」といった具合に、用途・顧客別のログインページを個別に設けているような場合が該当します。1つ1つの個別ログインページは noindex で非表示として、代わりに「総合ログイン案内ページ」(それぞれの顧客向けのログインページへ誘導するリンクが設置されている)を検索結果に表示されるようにすることで、不適切なログインページへアクセスしてしまい、何度 ID とパスワードを入力してもログインできないといった事態を避けることができるでしょう。
繰り返しますが、noindex は「非表示」なので、検索エンジンによっては一定の条件を満たした場合にそのまま URL を表示することもあります。個人情報などセンシティブな情報を扱うページは noindex ではなく、認証をかけるなどの方法で閲覧を制限することを推奨します。
以下、よくある質問とその答え。
Q) Google のインデックス登録システムが新しくなり、ウェブページをレンダリングするようになった関係で、全てのページのクロールを許可するように聞いた。noindex をすることで、インデックスや検索順位に影響することがあるか?
A) 全くない。なぜなら (1) noindex は検索結果に非表示にするものでレンダリング云々とは関係がないし、(2) Google 自身も世の中には様々な理由・事情で noindex が必要とされるケースがあることも理解しているし、(3) パンダアップデート対策アドバイスとして noindex を使うことを Google がアドバイスしている。必要に応じて自由に noindex を利用して構わない。
Q) 機械的に数万単位で生成された、SEO用のページがある。パンダアップデートが怖いので対応したいが、削除しなくても noindex をつければ十分か?
A) 理論上は noindex を書いても物理的にページを削除しても同じ解釈だと思う。ただ、「検索エンジン対策のために自動生成させている」という悪意の認識があるならば、物理的に生成されないように対処すれば将来的には良いのでは?
Q) Webページを検索結果から今すぐ削除したい。noindex を加えれば十分か?
A) ページを検索結果から削除したい時は、noindex ではなくて、Googleウェブマスターツールで提供されている「URLの削除」(古いコンテンツの削除)を利用すること。
nofollow:ページ内の発リンクを巡回させない / リンク評価に影響を与えない
robots meta タグの nofollow は、ページ内の発リンク(外部のページへ向かうリンク)を巡回させないディレクティブです。近年は、アルゴリズムのリンク評価に影響を与えないようにするための指示としての重要性が高くなっています。
例1) ページ上の全てのリンクを nofollow にする
<meta name="robots" content="nofollow">
(全てのクローラに対して、ページの発リンクを巡回しないように指示)
例2) ページ上の特定リンクのみ nofollow にする
<a href="www.example.com/" rel="nofollow">sample$lt;/a$gt;
noindex 同様に、クローラのアクセス自体を拒否したい場合は、robots.txt で disallow を指定する方が確実です。
nofollow の robots meta タグは次のようなケースで役立ちます。
- ガイドライン違反を回避する(広告の扱い):検索エンジン(特にGoogle)は、金銭授受により取引されたリンクによって検索順位を操作する行為を厳しく取り締まっています(いわゆる有料リンク問題)。例えば「記事広告から広告主へリンクを張る」「金銭を得た結果としてリンクを設置する」といった場合、そのサイトオーナーは各々のリンクに rel="nofollow" を加えて、その対象リンクが検索順位に影響を及ぼさないように明示することで、ガイドラインを守ることができます。
- ガイドライン違反を回避する(スパムへの加担):特にUGC(User-Generated Content)を扱うサイトオーナー、例えば無料ブログサービスの運営や、誰もが自由に参加・書き込みできるコミュニティサイトや掲示板サイトを運営している場合に有効です。不特定多数のユーザーが書き込み可能な場所はウェブスパム(ここではSEOのターゲットサイトへの不正リンクを大量設置する行為)の温床となりやすく、それらスパムリンクを放置することで問題のあるサイトとみなされる可能性があります。ユーザーが投稿する場すべてに nofollow を適用してランキング計算対象から外しておくことで、ガイドラインへの抵触を回避することがでます。
- 問題ありと指摘されたリンクを無効にする:人工リンクのような不適切な外部リンク構築に手を染めてしまった結果、Google からガイドラインへの違反を指摘されたり、自動的にアルゴリズムで検索順位を下げられる(いわゆるペナルティ)ことがあります。こうした問題に対処するためには、問題のあるリンクそのものを削除しなければなりませんが、記事広告のような広告としてユーザーにリンクを提示する意味があるようなケースでは nofollow を加えてランキングには影響を及ぼさないように対処することも有効です。
以下、よくある質問とその答え。
Q) 某大手会社が URL/?rel=nofollow という記述をしていた(例 www.example.com/?rel=nofollow )が、これもリンク巡回拒否と同じ指示になるか?※ 実話、
A) 勘違い。そういった記述方法はない。
Q) PageRankスカルプティング(sculpting)なる対策がSEOに有効だという記事を読んだ。今でも効果があるのか?
A) 2010年以前にすでに否定された。Google・マットカッツ氏自身がかつて推奨してしまったためにSEO業界で広がったのだが、PageRankスカルプティングは検索エンジンのためだけの行為にすぎないので、その後、同氏自身が否定している。PageRankの流れをコントロールするために nofollow の記述を最適化する行為は意味がない(効果がない/時間の無駄)。
Q) クロールを拒否することでインデックス登録や検索順位に悪影響はないのか?CSS や画像、JavaScript を全てクロール許可しなければならないと聞いた。
A) A) 問題ない。この手の疑問を思い浮かべる方は、「ロボット制御プロトコル」(REP)という検索各社がサポートする標準仕様に基づいているのだから、ディレクティブの意図と当然期待される結果と影響以外の、予想外の不利益をサイトオーナーが被ることは基本的にない、という REP の趣旨と役割を理解してほしい。あくまでインデックス登録プロセスにおけるクローラの制御であって、ランキングの制御ではない。
さて、日米問わず勘違いが多い話だが、(1) Google はあらゆるファイルをクロール許可せよとは一言も言っていないし、(2) クロール拒否全般が悪いこととも言っていない。Google がウェブマスターに伝えたいことは、JavaScript や CSS もレンダリング(描写)するようになったので、ウェブページの主コンテンツを把握できるように許可することを推奨しているだけで、あらゆるものを許可せよとはいっていない。同社自身も、例えば広告関連技術やサードパーティーのASPを利用しているために許可/拒否の制御がサイトオーナーでは行えない場合があることも理解しており、そうしたものは「放置してよい」と説明している。
Q) nofollow を加えると、そのリンク先ページはインデックスされないのか?(ページ上から巡回を拒否する=クロールしないのだから、インデックスもされないという理解であっているか?)
A) いいえ。あくまで対象ページに書いてあるリンクを辿らない(nofollow)という意味なので、その対象ページにリンクを張っている他のページが存在すれば(その他のページ経由で見つけて)インデックスすることになる。リンク先ページも検索結果に表示させたくないなら、そのページにも noindex を加えること。
noindex,nofollow / none:検索結果に表示もさせないし、リンクも辿らせない
noindex、nofollow を組み合わせて、検索結果への表示も拒否し、ページ上の発リンク巡回も拒否することができます。noindex と nofollow の間に , (カンマ)を入れます。none と記述しても同じです。
例1) <meta name="robots" content="noindex,nofollow">
(全てのクローラに対して、ページの発リンクを巡回しないように指示)
例2) <meta name="robots" content="none">
※ none と記述しても noindex,nofollow の意味になります。
noindex,follow:クローラの導線は確保したい時に利用
サイト内の各ページへリンクを張っているサイトマップ(ユーザー向けのサイトマップ)それ自体は検索結果で表示したくないけれども、そのリンクをクローラに辿らせたい時には noindex,nofollow の組み合わせが有効です。
例)<meta name="robots" content="noindex,follow">
商品検索結果ページのインデックスを制御したいけれども、個別商品へのリンク導線は確保したい時などが想定されます。
nositelinkssearchbox:検索結果にサイトリンク検索ボックスを表示させない
サイトリンク検索ボックスを表示させたくない場合は、次のコードをheadセクションに記述します。
<meta name="google" content="nositelinkssearchbox">
※ サイトリンク検索ボックスは Google しか提供していないので name="google" になっている
そもそも「サイトリンク検索ボックスって何?」という方も多いと思いますが…2014年9月中旬から、一部のサイトが検索結果に表示される時に、サイトリンク検索ボックスを伴って表示されるようになりました。メジャーなサイトの多くに表示されるもので、その検索窓から検索すると、対象サイトのドメイン名 site: で絞り込んだ Google検索結果、あるいはそのサイト独自のサイト内検索結果にリダイレクトされるようになります。
このサイトリンク検索ボックス、実はあまり評判が良いものではなく、例えば Amazon.co.jp など本機能のリリース直後に削除している大手サイトもちらほらあります。理由は、(1) site: 検索結果の場合はライバル企業の広告も検索結果に表示される、(2) 独自サイト内検索結果に誘導しても適切な絞り込み条件やカテゴリが適用できない、(3) そもそも利用者がいない(機能に対する検索利用者の認知が低いため)といった事柄が挙げられます。
サイトリンク検索窓が表示されることで、かえってユーザー体験が損なわれる可能性があります。従って、自分のサイト名や会社名で検索をして、サイトリンク検索ボックスが表示されるか否かを確認のうえ、表示されるのであれば実際に検索をしてみましょう。もし site: で表示するのであれば、基本的に nositelinkssearchbox で表示させなくて問題がありません。独自サイト内検索に誘導する場合でも、本当にユーザー体験の向上に寄与しているかどうか GA などのウェブ解析で検証すると良いでしょう。
cf. Google、サイトリンクの検索ボックスを拒否可能に METAタグ nositelinkssearchbox 追加
notranslate:翻訳版へのリンクを表示させない
ユーザーのブラウザ設定言語とページのコンテンツ言語が異なる場合に、検索結果に翻訳版へのリンクが表示されることがありますが、このリンクを非表示にするのが notranslateです。
<meta name="google" content="notranslate">
自動翻訳が上手くいかないような言語やトピックを扱っていて、翻訳版で閲覧してほしくないようなケースで使うと良いでしょう。リンク表示を制御するディレクティブなので、検索順位には影響しません。
noarchive (nocache):Googleにページキャッシュをさせない
Google 検索結果には、クローラが取得したキャッシュ(Googleが最後にクロールした時に表示されていたページ)を閲覧するリンクがあります。そのキャッシュへのリンクを表示させないのが、noarchive ディレクティブです。Google はnoarchive 、Bing は nocacheとnoarchive どちらでも OKです。
例1) <meta name="robots" content="noarchive">
(全ての検索エンジンにキャッシュリンクを許可しない)
例2) <meta name="googlebot" content="noarchive">
(Googleのみキャッシュリンクを許可しない)
例3) <meta name="robots" content="nocache">
(Bing は noarchive も nocache も同様に扱う)
速報系ニュースメディアのように、公開直後に何らかの変更が加えられる可能性を持つ特性のメディアを運営している場合は、noarchive を加えることで古くなった情報をキャッシュ経由で閲覧させることを制限できます。また、某協会系の方面より「Googleにキャッシュを拒否すると検索順位が下がる」というデタラメの情報が流れていると耳にしたことがありますが、(1) デタラメ、(2) そもそも noarchive はキャッシュへのリンクを非表示にするのであって、キャッシュを拒否するわけではない、ということで誤った情報に惑わされないようご注意ください。
nosnippet:Google検索結果にスニペット(説明文)を表示させない
nosnippet ディレクティブは、検索結果のスニペット(説明文を表示する欄)を表示させない記述です。スニペット枠の情報を表示しないという指示なので、テキスト説明文だけでなく、ページのサムネイル(画像、該当時)など同欄内の全ての情報が非表示となります。Google と Bing 共にサポートしています。
例)
<meta name="robots" content="nosnippet">
一般的には使わないと思います。クリック率を下げたい時とか?(どんな時だ)。不適切な説明文テキストが表示される、例えば日本語サイトなのに英語版が表示されるといったケースに利用を検討する方がいるかもしれませんが、その場合は nosnippet を使うのではなくて、該当ページ内の調整をして解決すべきことだと思います。
noimageindex:画像検索結果に画像を表示させない
noimageindex は画像検索結果に画像を表示させないためのディレクティブです。Google のみサポートしている模様です(詳細不明)。
例)
<meta name="robots" content="noimageindex">
画像をインデックスから即座に削除したい場合は、ウェブマスターツールから「削除リクエスト」を使います。
noodp:DMOZ(ODP)に掲載された説明文をスニペットに用いることを拒否
noodp は、生ける屍のような状態のディレクトリサイト・DMOZ (Open Directory Project)に掲載されている説明文をスニペットとしてウェブ検索結果に利用されるのを拒否するための指示です。Google と Bing 共にサポートしています。
例)
<meta name="robots" content="noodp">
2015年1月現在、noodp は次のような取り扱いが望ましいと考えます。
ODP ディレクトリにサイトが掲載されていない場合:noodp robots META タグを記述する必要はありません。
ODP ディレクトリにサイトが掲載されている場合:デフォルトで noodp の利用を検討し、意図しない(不適切な/不相応な)説明文がスニペットに表示されることを防止します。
背景は次の通り。
- DMOZ / ODP が何かわからない方も多いと思いますので、最初に検索エンジンと ODP の関係について整理します。Google は、ウェブ検索結果に表示するリンク先URLが ODP にも登録・掲載されている場合、そのスニペットに同社のアルゴリズムで自動生成した説明文ではなく、ODP に掲載された説明文を掲載することがあります。それを拒否して、Google の自動生成アルゴリズムに委ねるよう指示するのが noodp という robot META タグです。
- 大抵のケースで ODP の紹介文は検索結果に引用・表示する文章として不相応・不適切であることから、noodp の利用をお勧めします。理由は2つあります。
- 理由(1) 不適切な説明文が表示される可能性がある:第1に、現在登録されているサイト紹介文は ODP に初めて掲載された当時のままであることが多く、現在のサイトの内容を反映していない不相応な(古い)紹介文である可能性が高いからです。登録済みで今日まで運営されてきたWebサイトであればある程度の時間が経過していると思いますが、その間にこまめに DMOZ 掲載紹介テキストをメンテナンスしてきたサイトオーナーは稀でしょうし、大半の人は DMOZ の存在自体を忘れていることでしょう。長く運営してくれば企業の業務内容も変わるでしょうし個人サイトで扱う話題も変化しているはずです。
- 理由(2) DMOZ掲載文のメンテナンスは現実的ではない:「ならば DMOZ の紹介文を修正してもらえばいいじゃないか」と考えるかもしれませんが、2015年1月現在の DMOZ は積極的に活動しているわけではなく、ボランティアで運営されているサイトですから、説明文の修正依頼をかけても反映されません(カテゴリによる)。仮に反映されたところで、ここは広告スペースではなくディレクトリ検索サイトですから、簡潔に、客観的な、ざっくりとした紹介文に置き換わるだけです。
- 以上の理由から、noodp ディレクティブを使用して検索エンジンに ODP掲載データを使わないように指示し、アルゴリズムによる自動生成に委ねた方が効果的かつ効率的と言えます。
そもそも ODP は2015年1月現在、キーワードを入れて検索しても常にゼロ件表示でまったく動作していませんし、市場における役割は既に終了したに等しい状況にあります。そんな ODP にこれから新規に登録する価値は SEO 的にも全くありませんので、まだ未登録の場合はスルーで全く問題ありません。
unavailable_after:指定時間経過後にインデックスから削除する
unavailable_after は比較的新しいロボット排除プロトコルの1つです。2007年に Google から正式に発表されたもので、指定した時間を過ぎた後は自動的にウェブ検索結果から当該ページを消す働きをします。Google のみサポートしています。
例)
<meta name="googlebot" content="unavailable_after">
例)2015年8月1日午前7時を過ぎたら非表示にしたい場合
<meta name="googlebot" content="unavailable_after: 1-Aug-2015 07:00:00 JST">
unavailable_after: の後ろに続けて RFC 850フォーマット(DD-Mon-YY HH:MM:SS TIMEZONE)で時間を指定します。
unavailable_after METAタグは次のようなケースで役立ちますが、注意すべき事項もあります。
- 期間限定で情報発信したいウェブページの制御に適しています。例えば、一定時間経過後は必ず終了するであろうオークション出品ページや、求人情報ページなどが挙げられます。期間限定のクーポン配布サイトや、7日間限定の大バーゲンセール会場サイト、5日間だけは無料で誰でも閲覧できる会員制メディアの記事なども適しているでしょう。
- 企業にとって有効期限が切れたことが、そのままユーザーにとって不要になるわけではない点に注意してください。例えば、毎年新版が発売される年賀状作成ソフトウェアが、新版が出るたびに旧版サイトを検索結果で非表示にすることは正しくありません。古いバージョンのソフトウェアを使い続けるユーザーもいますし、彼らはその旧版の情報(仕様、トラブルシューティング、活用方法、取扱説明書)を求めて検索するものです。
cf. グーグル、"unavailable_after" METAタグの正式運用を開始
noindex 同様に、検索結果に非表示になるだけでインデックス登録システム自体には残るので、完全に削除したい場合はウェブマスターツールで提供されている削除リクエストを利用する必要があります。
<meta name="robots" content="index,nofollow">
検索結果には表示して良いが、リンク先は辿らない(評価対象外)にしてほしい
Robots meta tag and X-Robots-Tag HTTP header specifications
https://developers.google.com/webmasters/control-crawl-index/docs/robots_meta_tag
Appendix: Google's website crawlers
https://developers.google.com/webmasters/control-crawl-index/docs/crawlers
Multiple robots meta tag?
https://productforums.google.com/forum/#!topic/webmasters/ApSmuoRvGmU
メタタグを使用して検索インデックス登録をブロックする
https://support.google.com/webmasters/answer/93710?hl=ja
Google がサポートしているメタタグ
https://support.google.com/webmasters/answer/79812?hl=ja
Bing Robots Metatags
http://www.bing.com/webmaster/help/which-robots-metatags-does-bing-support-5198d240