




だんだんプロセスの話が最近の話題に近づいてきたところで恐縮であるが、CESなどで製品ロードマップのアップデートが相次いだので、プロセスの話はお休みして、主要メーカーの製品ロードマップをお届けしよう。

GeForce GTX 780 Ti
1番手はNVIDIAのGPUである。前回は昨年10月だったので、まずはそこからの差分を解説しよう。
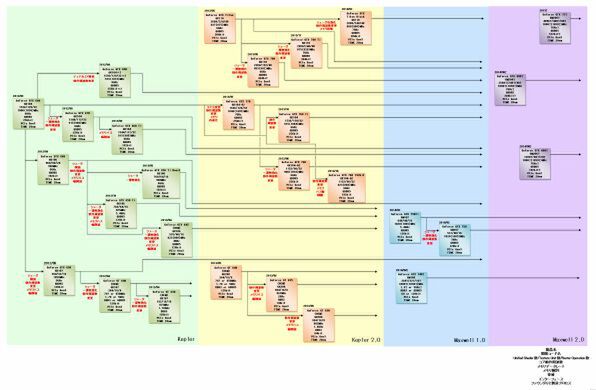
2012~2014年のNVIDIAロードマップ
前回からの大きな違いとしては、GK110コアの製品が大幅に拡充されたことだ。それまでは「GeForce GTX Titan」と「GeForce GTX 780」の2製品で、これで打ち止めかと思ったのだが、予想に反して2013年11月に「GeForce GTX 780 Ti」を投入した(関連記事)。
本来GeForce GTX Titanなどに使われるGK110コアは5GPC(Graphics Processing Cluster)構成で、各々のGPCが5つのSMXというユニットを内蔵する。1つのSMXは192基のシェーダーで構成されるので、フル構成だと192×5×3=2880基のシェーダーが搭載される計算になるが、GeForce GTX Titanではこのうち1つ、GeForce GTX 780では3つのSMXを無効化してリリースしていた。

192個のCUDAコアで構成されているKepler世代のSMX(Streaming Multiprocessor eXtreme)
これは性能の差別化という観点もあるが、533mm2もの巨大なダイとなると、歩留まりは猛烈に悪くなりがちである。これを回避するためには、欠陥が多少あっても、それを含むSMXユニットを無効化してしまえばいいわけで、実際GeForce GTX Titanが14 SMX構成なのはそうした理由と思われる。
しかし、GeForce GTX Titanの出荷開始から半年ほど経過し、ある程度歩留まりが改善してきた、もしくは歩留まりの見極めがついたのだろう。GeForce GTX 780 TiではすべてのSMXを有効にしたフル構成としてリリースされた。

GeForce GTX 780 Tiでは、15個すべてのSMXを有効にしている
おまけに動作周波数もやや引き上げられ、メモリーも7Gbpsまで高速化されており、明らかに上位製品であるGeForce GTX Titanを上回る性能を発揮した。さすがにそうなるとGeForce GTX Titanの立場がなくなることもあり、GK110では本来搭載されていた倍精度浮動小数点演算のサポートを切る形で差別化を図っている。とはいえ数値演算とかはともかく、ゲームに関しては間違いなくGeForce GTX 780 Tiの方が高速である。
これに続き、今年2月18日には、GeForce GTX Titanの上位製品として「GeForce GTX Titan Black」も発表した(関連記事)。シェーダー構成は15 SMXとフルに有効にされ、動作周波数はGeForce GTX 780 Tiより微妙に引き上げられた上、メモリーは従来の倍の6GBになり、加えて倍精度浮動小数点演算が有効にされた。要するに「全部アリ」のハイエンド版である。


GeForce最上位機種「GeForce GTX Titan Black」
用途としては、もうゲーム用というよりは限りなくGPGPU向けである。頑張ればもうすこし動作周波数を上げられるかもしれないが、消費電力や発熱の観点からすると大幅に引き上げるのは難しく、今度こそGK110はここで打ち止めということになりそうだ。
このGeForce GTX Titan Blackと同時に発表されたのが、Maxwellコアの「GeForce GTX 750 Ti」と「GeForce GTX 750」である。コード名がGM106ということからわかる通り、これはメインストリームの中間から下、といった位置付けになる。これはNVIDIAの資料からも明らかだ。

GeForce GTX 750 Tiと同750は、メインストリームの中間から下といった位置付け
Maxwellコアは、基本的なシェーダー(CUDAコア)の内部構造がまだ明らかになっていないが、これまでのSMXの内部を4つに分解したようなSMMと呼ばれる構造で構成される。

Maxwellでは、コントロールロジックを効率化。SMXを4つに分けたSMM(Steaming Multiprocessor Maxwell)と呼ばれるユニットで構成される
各々のSMMは128基のシェーダーを搭載している。この結果、これまでは192シェーダーごとに1つのコントロールロジックだったのが、今度は32シェーダーごとに1つのコントロールロジックとなるわけで、コマンドの粒度(どれだけ細かく並列処理を行なえるかの度合い)が6倍になったことになる。
ただこの粒度の改善だけでは35%の性能改善や2倍の性能/消費電力比は実現出来ないわけで、このあたりはシェーダーそのものにも手が入っていると思われる。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")



















