




Atomのパイプライン構造を
順に解説
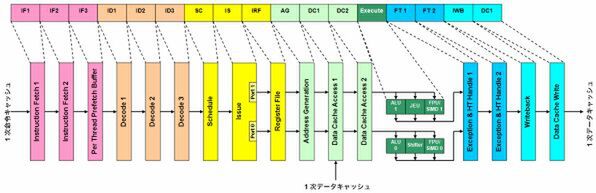
Atomのパイプライン構造図
Atomのパイプライン構造を詳細に見ていこう。まず「IF1」~「IF3」は命令フェッチとなる。最初の2ステージで1次命令キャッシュからデータを取り込み、これをスレッドごとの「Prefetch Buffer」に格納するのがIF3となるようだ。命令フェッチはシングルスレッドの場合、おおむね8byte/サイクル程度で(ピークではもう少し上)、2スレッドではそれよりやや落ちる。2命令/サイクルの命令フェッチができれば問題ないので、この程度で十分と判断しているようだ。
続く「ID1」~「ID3」が命令デコードである。命令デコーダーそのものは、Core iシリーズで言うところの「Simple Decode」に相当するデコーダーが2つと、マイクロコードを利用した「Complex Decode」が用意されている。このデコーダーはSimple Decodeと同じく、ひとつのx86命令をひとつのμOpに変換する……と言うよりも、ひとつのμOpに変換できるx86命令しか扱わない。ちなみにインテルによれば、一般的なプログラム実行時の動作状況を検証してみると、平均で96%の命令が、ひとつのμOpにそのまま変換できるという。
ちなみにこのデコーダー段は、Macro Fusionも搭載している(説明はこちら)。デコーダーは3ステージあるが、3ステージ目ではスレッド別に、デコード済μOpをキューに格納する。これはCore iシリーズとやや実装の異なる部分である。このキューは各スレッドあたり16μOpを格納できるようになっており、ハイパースレッディングを無効にすると32μOpとなる。
続く「SC」「IS」「IRF」がスケジューラー段となる。まずスケジューラー段ではキューからμOpを取り出し、これを続く「Issue」に渡す。Issueでは、どちらの命令ポートで実行するかが決定される(後述)。パイプライン図ではここから線が2本出ているように見えるが、実際は「どちらの命令ポートで処理するか」を示す1bitのタグがμOpに付加されるだけで、物理的にはまだ一本化されている。続く「Register File」は、実際に命令を処理するにあたって、どのRegister Fileを使うか割り当てる部分だ。
「AG」「DC1」「DC2」と続くのが、データキャッシュからのデータ取り込みである。「Address Generator」によって取り込むアドレスを確定し、それに相当するデータを2サイクルかけてDC1/DC2のステージで取り込み、先にIRFで確定したRegister Fileに格納する。もしここでキャッシュミスが発生した場合、スケジューラー段に処理が戻り、実行中のスレッドは待機状態となって、もう片方のスレッドの命令を取り込んで処理再開となる。これによるペナルティは4サイクルほどですむわけだ。
データをRegister Fileに格納し終わったら、いよいよ実行である。先にも触れたとおり、Atomでは命令発行ポートが2つしかない。この各々のポートに接続されている実行ユニットは、以下のような分類になる。
| 両方のポートに用意されているユニット |
|---|
| レジスタ間のMove |
| 汎用レジスタ/SIMDレジスタへの加算(整数/浮動小数点) |
| 汎用レジスタ/SIMDレジスタの論理演算 |
| Port 0にのみ用意されているユニット |
| メモリーへのLoad/Save |
| Shift/Shuffle/Pack |
| 乗除算 |
| そのほか複雑な演算 |
| Port 1にのみ用意されているユニット |
| 分岐処理 |
| LEA命令 |
簡単な演算命令「だけ」ならば1サイクルあたり2命令となるが、一般的な「ロード+演算」命令だと、1サイクルあたり1命令が現実的なスループットである。
また、パイプライン図では「Execute」を1サイクルとしている。ただし、簡単な命令※1は、遅延が1サイクルで済むが、複雑なもの(例えば乗除算)に関しては当然ながらもっと遅延が多くなる。
※1 「両方のポートに用意されているユニット」に相当するもの。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























