




前回まではインテルとAMDのプロセス技術からCPUを見てみた。今回からはCPUアーキテクチャーの変化について、その内部構造の変化を見ながら解説していく。インテルCPUの場合、「P6」アーキテクチャーが現在まで続く、CPUアーキテクチャーの基本となっている。つまり、P6アーキテクチャーから順にたどっていくと、インテルCPUの進化を俯瞰できるというわけだ。それではP6アーキテクチャーについて解説しよう。

別のダイの2次キャッシュを1パッケージに収めたため、巨大なパッケージとなった「Pentium Pro」。内部アーキテクチャーは長くインテルCPUに受け継がれることに
P6アーキテクチャーの処理パイプライン
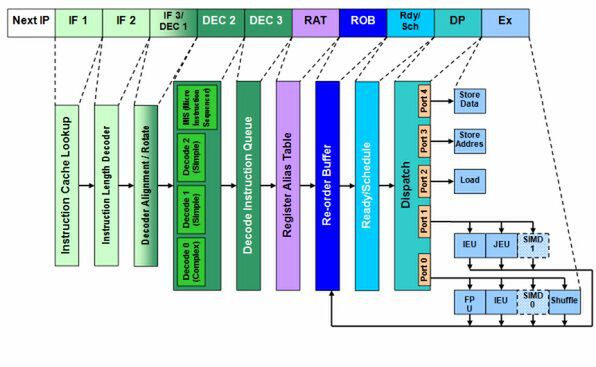
図1 Pentium Proの内部構造図
まず図1は、P6アーキテクチャーの初代である「Pentium Pro」の内部構造である。この内部構造そのものは、Pentium IIIまでほぼ変わらず継承された。内部的に大きな変更点は、Pentium IIでの「MMX」命令への対応と、Pentium IIIでの「SSE」命令への対応ぐらいだ。
これらに対応するために、Pentium II以降では実行ステージ(Ex、Execute)に「SIMD 0」「SIMD 1」が追加されたほか、フェッチ~デコード(IF1~DEC3)でMMX/SSEを扱えるようになった。Pentium IIIではSSEレジスタが新規で追加になったが、この程度の変化でしかない。これについてはまた後で触れることにする。
一般にP6アーキテクチャーは、「10ステージのアウトオブオーダー」パイプラインとして認識されているが、実はこのほかに(図1には入れていないが)2ステージの「Retirement」※1という処理があり、実際には計12ステージになる。また、パイプライン全体のうちアウトオブオーダーで動作しているのは、「Ready/Scheduler」(Rdy/Sch)から実行ステージまでの3ステージに過ぎず、「Instruction Cache Lookup」(IF1)~「Register Alias Table」(RAT)やRetirementは、いずれもインオーダーで動作している。さらに、IF1の前にある「Next IP」というステージは、通常ではパイプラインの中に加味しないため、これも取り込むと13ステージという計算になる。
※1 実行結果をレジスタに書き戻したり、ステータスレジスタの値を更新したり、といった後処理。
各ステージで何をやっているかを、もう少し細かく説明しよう。まずNext IPだが、これは「次の命令はメモリー中のどこから開始されるか」を計算するものだ。IPとはInstruction Pointer(命令ポインタ)と呼ばれるもので、「現在実行中の命令が置かれているメモリーアドレス」を示す。
x86の場合、それぞれの命令や命令の前に付くプリフィックスによって、命令の長さが変わる「可変長命令」方式を採用している。例えば、今の命令がアドレス「0x00001000H」にあったとして、「次の命令はどのアドレスか?」は条件によって異なる。そのため次の命令の位置を計算しないと、命令を正しく取り込めないことになる。この計算をするのがNext IPというわけだ。
もっとも実際にはP6の場合、1サイクルあたり複数個の命令を取り込むことになる。だから厳密にはNext IPが計算するのは「次の命令」というよりも、「今読み込み終わっている複数個の命令の『次』の命令」になる。図2は毎回8byteずつ読み込んだ場合の例だが、左側で星マークがついている部分が「Next IP」に相当する場所になる。次の命令のアドレスが特定できたら、それをベースにキャッシュから命令を読み込んで(フェッチ)それぞれ並べる。ここまでの作業をIF1~IF3のステージで行なっている。

図2 Next IPが命令位置を計算するタイミング(黄色いマークのところ)
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















